

Was ist Qualität?
Dazu gibt es viele Definitionen. Im Allgemeinen bedeutet Qualität den Grad zu dem eine Eigenschaft oder ein Merkmal eines Produktes eine gegebene Anforderung erfüllt. Bezogen auf ein Softwareprodukt bedeutet z.B. Wartungsqualität das Maß an Wartbarkeit, welches die Software besitzt. Zum Erfassen der Qualität muss man sich Gedanken über geeignete Metriken und Skalen machen.
Wann kann man mit dem Testen aufhören?
Hierzu gibt es mehrere Testendekriterien:
- Alle Testfälle wurden ohne Befund absolviert
- der Test x Stunden gedauert hat
- der Test den Aufwand y beansprucht hat
- n Fehler gefunden sind
- z Stunden lang kein Fehler mehr gefunden wurde
- die durchschnittlichen Kosten für die Entdeckung eines Fehlers x Euro überschreiten
- Alle Testfälle wurden ohne Befund absolviert
- der Test x Stunden gedauert hat
- der Test den Aufwand y beansprucht hat
- n Fehler gefunden sind
- z Stunden lang kein Fehler mehr gefunden wurde
- die durchschnittlichen Kosten für die Entdeckung eines Fehlers x Euro überschreiten
Was ist eine Anforderungsspezifikation und welchen Zweck hat diese?
Die Anforderungsspezifikation ist Grundlage für die Analyse und die Entwurfsphase und somit essentiell für den weiteren Entwicklungsprozess. Sie definiert die Wünsche des Kunden an das System (ausformuliert und als vertragliche Grundlage im Lastenheft) und dient als Grundlage für den späteren Systemtest.
Welche Arten von Anforderungen gibt es?
Funktionale und Nicht-Funktionale. Funktionale Anforderungen machen konkrete Aussagen darüber, was das System leisten soll. Nicht-Funktionale beziehen sich auf Eigenschaften wie Speicherverbrauch, Reaktionszeit oder Aussehen der Benutzeroberfläche.
Was ist eine Metrik und welche Softwaremetriken gibt es?
Eine Metrik ist eine Abbildung einer Eigenschaft (z.B. eines Softwaresystems) auf eine skalare oder vektorielle Größe einer vorher festgelegten Skala. Hierbei kann eine Metrik als Modell angesehen werden, da sie Verkürzungs-und Abbildungsmerkmal erfüllt. Metriken sind deskriptiv/präskriptiv (beschreiben Zustand wie er ist bzw. sein soll), diagnostisch/prognostisch (beschreiben bestehenden oder zukünftigen Zustand) und robust bzw. unterlaufbar (d.h. es gibt (k)eine Möglichkeit den Wert der Metrik zu beeinflussen). Eine Pseudometrik ist eine Metrik, die sich aus geschätrzten Werten ergibt, da man sie nicht direkt durch Messen eines Wertes ermitteln kann. Z.B. kann man den BMI nicht direkt messen, sondern benötigt die Hilfsgrößen Größe und Gewicht, um den Wert der Metrik dann zu berechnen. Hier eine kleine Auswahl an Metriken:
Komplexität nach McCabe
Man betrachtet ein Flussdiagramm und berechnet die Komplexität des Programms zu:
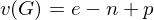 wobei e die Zahl der Kanten, n die Zahl der Knoten und p die Zahl der Außenverbindungen ist. Dies entspricht der zyklomatischen Zahl eines Graphen. Die Metrik ist sehr einfach und liefert nicht immer aussagekräftige Werte, da z.B. komplexe Datenstrukturen bei der Berechnung keine Beachtung finden.
wobei e die Zahl der Kanten, n die Zahl der Knoten und p die Zahl der Außenverbindungen ist. Dies entspricht der zyklomatischen Zahl eines Graphen. Die Metrik ist sehr einfach und liefert nicht immer aussagekräftige Werte, da z.B. komplexe Datenstrukturen bei der Berechnung keine Beachtung finden.
Software Science nach Helsted
Hier liegt die Idee zugrunde, dass ein Programm zum größten Teil aus Operanden und Operatoren besteht. Helsted definiert:
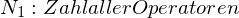
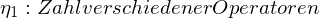
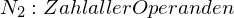
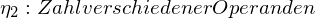
Hieraus werden Metriken wie z.B. die Zahl der Elementarentscheidungen eines Programmieres abgeleitet. Die Metriken sind allerdings nicht überprüft und deren Aussagekraft ist somit eher fraglich.
COCOMO
Pseudometrik zum Ermitteln der Kosten eines Softwareprojektes nach Boehm. Die Formeln sind aus großen Mengen archivierter Projektdaten abgeleitet und verifiziert. Einflussfaktoren auf die Projektlaufzeit sind:
- DSI (Delivered Source Instructions, entspricht Lines of Code)
- Art des Projektes (Organic: kleine Projekte, in denen keine Entwicklung von nichttrivialen Algorithmen von Nöten ist, Semidetached: mittlere Projekte, wobei das Entwicklerteam aus erfahrenen und unerfahrenen Mitarbeitern besteht, Embedded: Entwicklungsprojekte für neuen Einsatzbereich in einem großen Projektteam)
- Anforderungen an die Verlässlichkeit der Software
- Komplexität des Produktes
- Erfahrung der Entwickler in der Programmiersprache
- Einsatz von Software Tools
...
Je nach Menge der Daten, die zu einem Projekt vorliegen, kann die Schätzung mit unterschiedlichem Detaillierungsgrad erfolgen. Hier wird zwischen den 3 Schätzungsarten Basic,Intermediate und Detailed unterschieden.
Objektorientierte Metriken
Chidamber und Kemerer definierten 1994 verschiedene Metriken für die objektorientierte Programmierung.
Weighted Methods per Class (WMC)
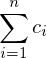
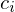 : Komplexität der Methode
: Komplexität der Methode 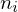
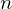 : Zahl der Methoden
: Zahl der Methoden
Depth of Inheritance (DIT)
Tiefe der Klasse im Vererbungsbaum
Number of Children of a class (NOC)
Anzahl der Unterklassen einer Klasse
Coupling between classes
Anzahl der Klassen, die eine Klasse benutzt
Response for a class (ROC)
Anzahl aller möglichen auszuführenden Methoden einer Klasse (d.h. Anzahl der Methoden der Klasse selbst + Anzahl der Methoden, die über Umwege, also z.B. durch Klassen, die die betrachtete Klasse benutzt, erreicht werden können.
Lack of cohesion in methods (LCOM)
Ermittelt den fehlenden Zusammenhalt der Methoden einer Klasse. Die Zahl sollte möglichst gering sein (am besten 0), da man innerhalb einer Klasse eine hohe Methodenkopplung erwartet (siehe Designprinzipien). Berechnungsvorschrift:
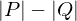 wenn
wenn 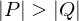 , sonst 0 mit
, sonst 0 mit
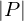 : Anzahl der Methodenpaare mit keinem gemeinsamen Attribut
: Anzahl der Methodenpaare mit keinem gemeinsamen Attribut
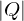 : Anzahl der Methodenpaare mit einem oder mehr gemeinsamen Attributen
: Anzahl der Methodenpaare mit einem oder mehr gemeinsamen Attributen
Komplexität nach McCabe
Man betrachtet ein Flussdiagramm und berechnet die Komplexität des Programms zu:
wobei e die Zahl der Kanten, n die Zahl der Knoten und p die Zahl der Außenverbindungen ist. Dies entspricht der zyklomatischen Zahl eines Graphen. Die Metrik ist sehr einfach und liefert nicht immer aussagekräftige Werte, da z.B. komplexe Datenstrukturen bei der Berechnung keine Beachtung finden.Software Science nach Helsted
Hier liegt die Idee zugrunde, dass ein Programm zum größten Teil aus Operanden und Operatoren besteht. Helsted definiert:
Hieraus werden Metriken wie z.B. die Zahl der Elementarentscheidungen eines Programmieres abgeleitet. Die Metriken sind allerdings nicht überprüft und deren Aussagekraft ist somit eher fraglich.
COCOMO
Pseudometrik zum Ermitteln der Kosten eines Softwareprojektes nach Boehm. Die Formeln sind aus großen Mengen archivierter Projektdaten abgeleitet und verifiziert. Einflussfaktoren auf die Projektlaufzeit sind:
- DSI (Delivered Source Instructions, entspricht Lines of Code)
- Art des Projektes (Organic: kleine Projekte, in denen keine Entwicklung von nichttrivialen Algorithmen von Nöten ist, Semidetached: mittlere Projekte, wobei das Entwicklerteam aus erfahrenen und unerfahrenen Mitarbeitern besteht, Embedded: Entwicklungsprojekte für neuen Einsatzbereich in einem großen Projektteam)
- Anforderungen an die Verlässlichkeit der Software
- Komplexität des Produktes
- Erfahrung der Entwickler in der Programmiersprache
- Einsatz von Software Tools
...
Je nach Menge der Daten, die zu einem Projekt vorliegen, kann die Schätzung mit unterschiedlichem Detaillierungsgrad erfolgen. Hier wird zwischen den 3 Schätzungsarten Basic,Intermediate und Detailed unterschieden.
Objektorientierte Metriken
Chidamber und Kemerer definierten 1994 verschiedene Metriken für die objektorientierte Programmierung.
Weighted Methods per Class (WMC)
: Komplexität der Methode : Zahl der MethodenDepth of Inheritance (DIT)
Tiefe der Klasse im Vererbungsbaum
Number of Children of a class (NOC)
Anzahl der Unterklassen einer Klasse
Coupling between classes
Anzahl der Klassen, die eine Klasse benutzt
Response for a class (ROC)
Anzahl aller möglichen auszuführenden Methoden einer Klasse (d.h. Anzahl der Methoden der Klasse selbst + Anzahl der Methoden, die über Umwege, also z.B. durch Klassen, die die betrachtete Klasse benutzt, erreicht werden können.
Lack of cohesion in methods (LCOM)
Ermittelt den fehlenden Zusammenhalt der Methoden einer Klasse. Die Zahl sollte möglichst gering sein (am besten 0), da man innerhalb einer Klasse eine hohe Methodenkopplung erwartet (siehe Designprinzipien). Berechnungsvorschrift:
wenn , sonst 0 mit: Anzahl der Methodenpaare mit keinem gemeinsamen Attribut: Anzahl der Methodenpaare mit einem oder mehr gemeinsamen AttributenWelche Skalen gibt es und wozu braucht man Skalen?
Skalen werden zur Abbildung der Messwerte einer Metrik benötigt. Hierbei gibt es unterschiedliche Skalenstärken, die von der Möglichkeit bestimmte mathematische Operationen (z.B. Mittelwertbildung) auf der Skala anzuwenden oder der Vergleichbarkeit der Werte abhängen.
Nominalskala
Beschreibt lediglich die Abbildung der Werte auf eine ungeordnete Menge. Man kann also die Werte nicht vergleichen oder Berechnungen durchführen.
Ordinalskala
Hier ist eine Ordnung definiert, allerdings gibt es keine Aussage über die Abstände zwischen den Messwerten. So lässt sich nur der Median ermitteln und nicht etwa der Mittelwert. Ein Beispiel aus der Softwaretechnik sind die 5 Stufen des CMMI. Hier ist auch nicht definiert wie groß z.B. das Intervall zwischen Stufe 2 und Stufe 3 ist.
Intervallskala
Im Unterschied zur Ordinalskala sind nun die Intervalle zwischen den Werten fest definiert, so dass sich z.B. auch der Mittelwert berechnen lässt.
Rationalskala
Diese Skala hat dieselbe Aussagekraft wie die Intervallskala, mit dem Unterschied, dass der Nullpunkt der Skala festgelegt ist und nicht wie bei der Intervallskala beliebig gewählt werden kann (Beispiel für beliebigen Nullpunkt: Datum hat unterschiedlichen Wert, ja nachdem welchen Kalender man benutzt). Beispiele: Masse, Druck, Stromstärke, Aufwand (bezogen auf ein Softwareprojekt).
Absolutskala
Zahlenwert der Skala ist nicht nur proportional zur gesuchten Größe, sondern ist die gesucht Größe selbst. Dieser Skalentyp tritt in der Softwaretechnik besonders häufig auf, da Werte oft durch Zählen bestimmt werden (z.B. Lines of Code).
Nominalskala
Beschreibt lediglich die Abbildung der Werte auf eine ungeordnete Menge. Man kann also die Werte nicht vergleichen oder Berechnungen durchführen.
Ordinalskala
Hier ist eine Ordnung definiert, allerdings gibt es keine Aussage über die Abstände zwischen den Messwerten. So lässt sich nur der Median ermitteln und nicht etwa der Mittelwert. Ein Beispiel aus der Softwaretechnik sind die 5 Stufen des CMMI. Hier ist auch nicht definiert wie groß z.B. das Intervall zwischen Stufe 2 und Stufe 3 ist.
Intervallskala
Im Unterschied zur Ordinalskala sind nun die Intervalle zwischen den Werten fest definiert, so dass sich z.B. auch der Mittelwert berechnen lässt.
Rationalskala
Diese Skala hat dieselbe Aussagekraft wie die Intervallskala, mit dem Unterschied, dass der Nullpunkt der Skala festgelegt ist und nicht wie bei der Intervallskala beliebig gewählt werden kann (Beispiel für beliebigen Nullpunkt: Datum hat unterschiedlichen Wert, ja nachdem welchen Kalender man benutzt). Beispiele: Masse, Druck, Stromstärke, Aufwand (bezogen auf ein Softwareprojekt).
Absolutskala
Zahlenwert der Skala ist nicht nur proportional zur gesuchten Größe, sondern ist die gesucht Größe selbst. Dieser Skalentyp tritt in der Softwaretechnik besonders häufig auf, da Werte oft durch Zählen bestimmt werden (z.B. Lines of Code).
Was ist CMMI?
CMMI bedeutet Capability Maturity Model (Integration) und ist eine Metrik zur Bestimmung des Reifegrades eines Softwareentwicklungsprozesses. Der Prozess als solches wird in die Prozesskategorien Projektmanagement, Prozessmanagement, Entwicklung und Unterstützung (Support) eingeteilt (beim CMMI für Development). Die Prozesskategorien werden erneut heruntergebrochen in Prozessgebiete, welche erneut in "Best Practices" untergliedert werden. Für jedes Prozessgebiet wird der Fähigkeitsgrad (0-5) bestimmt. Daraus wird dann der Fähigkeitsgrad für die Prozesskategorie bestimmt. Der Reifegrad des Gesamtprozesses ergibt sich dann als Mittelwert (evtl. auch gewichtetes Mittel) der einzelnen Fähigkeitsgrade der Prozesskategorien. Die Reifegrade werden in sogenannten Appraisals bestimmt, die die Firmen in der Regel Geld kosten und recht aufwändig sind. Sie lassen sich wie folgt beschreiben:
Initial
Jede Organisation hat diesen Reifegrad automatisch. In der Regel unterliegen die Projekte keinem definierten Prozess und sind eher "Zufallserfolge".
Managed
Die Projekte werden geführt, allerdings nicht durch einen unternehmensweiten Standardprozess. Das Management ist also noch nicht sehr involviert und der Prozess wird von den IT Abteilungen selbst initiiert. Projekte können in ähnlicher From wiederholt werden.
Defined
Es gibt einen unternehmensweiten Standardprozess für alle Projekte, der unter Umständen auch kontinuierlich verbessert wird.
Quantitatively Managed
Es werden systematisch Metriken erhoben, um die Qualität des Prozesses zu kontrollieren.
Optimizing
Der Prozess wird mit Hilfe der Metriken kontinuierlich verbessert.
Initial
Jede Organisation hat diesen Reifegrad automatisch. In der Regel unterliegen die Projekte keinem definierten Prozess und sind eher "Zufallserfolge".
Managed
Die Projekte werden geführt, allerdings nicht durch einen unternehmensweiten Standardprozess. Das Management ist also noch nicht sehr involviert und der Prozess wird von den IT Abteilungen selbst initiiert. Projekte können in ähnlicher From wiederholt werden.
Defined
Es gibt einen unternehmensweiten Standardprozess für alle Projekte, der unter Umständen auch kontinuierlich verbessert wird.
Quantitatively Managed
Es werden systematisch Metriken erhoben, um die Qualität des Prozesses zu kontrollieren.
Optimizing
Der Prozess wird mit Hilfe der Metriken kontinuierlich verbessert.
Was ist Softwaretechnik oder Software-Engineering?
Der Begriff Softwareengineering stammt aus den Mittsechzigern, als es während der Softwarekrise zu den ersten scheiternden Softwareprojekten kam. Erstmals überstiegen die Softwarekosten die Hardwarekosten.
Im Allgemeinen lässt sich Softwareengineering als ingenieurmäßiger, arbeitsteiliger Prozess der Enwticklung und des Betriebs großer Softwaresysteme mit Methoden, Prinzipien und Werkzeugen beschreiben. Als Methoden bezeichnet man zum Beispiel Vorgehensmodelle, die genau spezifizieren, welche Schritte bei der Entwicklung sowohl von technischer Seite als auch vom Management vorzunehmen sind. Prinzipien sind weitaus abstrakter. Wichtige Prinzipien beim Architekturentwurf sind zum Beispiel Abstraktion, Strukturierung, Hierarchisierung und Modularisierung. Werkzeuge sind Hilfsmittel zur Umsetzung der Methoden, z.B. CASE Tools (Computer Aided Software Engineering), IDEs, Versionsverwaltungssysteme, Kolaborationssysteme...
Im Allgemeinen lässt sich Softwareengineering als ingenieurmäßiger, arbeitsteiliger Prozess der Enwticklung und des Betriebs großer Softwaresysteme mit Methoden, Prinzipien und Werkzeugen beschreiben. Als Methoden bezeichnet man zum Beispiel Vorgehensmodelle, die genau spezifizieren, welche Schritte bei der Entwicklung sowohl von technischer Seite als auch vom Management vorzunehmen sind. Prinzipien sind weitaus abstrakter. Wichtige Prinzipien beim Architekturentwurf sind zum Beispiel Abstraktion, Strukturierung, Hierarchisierung und Modularisierung. Werkzeuge sind Hilfsmittel zur Umsetzung der Methoden, z.B. CASE Tools (Computer Aided Software Engineering), IDEs, Versionsverwaltungssysteme, Kolaborationssysteme...
Welche Prozessmodelle gibt es?
Prozessmodelle machen Aussagen über
- Organisation und Rollenverteilung
- Struktur der Dokumente
- Verfahren für die Anforderungserhebung
- das Vorgehensmodell
- Phasen, Meilsensteine, Prüfkriterien
- Notationen und Sprachen
- Werkzeuge
V-Modell
- Teil des Entwicklungsstandards für IT Systeme des Bundes (1992)
- erweiterte Version: V- Modell XT (2004) XT=Extreme Tailoring
- Meilenstein am Ende jedes Projektabschnitts
- unterstützt verschiedene Entwicklungsarten (inkrementell, komponentenbasiert, agil)
- trennt zwischen Auftraggeber- und Auftragnehmerprojekten
- Jedes Modell definiert Vorgehensbausteine und Projektdurchführungsstrategien
- Projektdurchführungsstrategien ordnen Entscheidungspunkte an
- Produkte müssen beim Erreichen eines Entscheidungspunktes fertig sein
- Vorgehensbaustein fasst Rollen, Produkte und Aktivitäten zusammen, die notwendig zur Lösung der Projektaufgabe sind
- Projekt muss aus mind. 4 Vorgehensbausteinen bestehen (Projektmanagement, Qualitätssicherung, Problem- und Änderungsmanagement, Konfigurationsmanagement)
- ggf. mehr Bausteine durch Tailoring
- Produkt wird durch genau eine Aktivität fertiggestellt
- Produkte hängen voneinander ab
- Rollen sind für Produkte verantwortlich und wirken an diesen mit
- wichtig zu merken: Auf jeder Ebene des Vorgehensmodells gibt es ensprechende Tests (Analyse->Abnahmetest, Grobentwurf->Systemtest, Feinentwurf->Integrationstest, Implementierung->Modultest)
- produziert Overhead bei kleinen Projekten
Unified Process
- auf Objektorientierung abgestimmte Methode durch Jacobsen (1998)
- basiert auf Use Cases
- iterativ: Prototypen in frühen Iterationen
- architekturzentriert
- Besteht aus 4 Phasen (Inception: Verstehen der Anforderungen, Risikobewertung, Use-Case Modellierung, 1. Fassung der Architektur/des Projektplans, Elaboration: Identifkation fehlender Anforderungen, grundlegende Architekturentscheidungen, Construction: Implementierung, Integration + Test, Ergebnis: Betaversion des Systems, Transition: Verbesserung des Systems bis es stabil läuft, Vervollständigung des Systems)
- Arbeitsabläufe, die in unterschiedlicher Intensität während jeder Phase durchgeführt werden: Requirements, Analysis, Design, Implementation, Test (ggf. mehr durch Tailoring, es kommen dann businessorientiertere Arbeitsabläufe hinzu)
- in jeder Phase gibt es mehrere Iterationen
- RUP ist die Ausprägung des UP zu vollwertigem Prozessmodell und wird durch IBM vermarketet
- Arbeitsabläufe werden hier durch UML Aktivitätsdiagramme visualisiert
- Vorteile: gute Dokumentation, guter Support
- Nachteile: geringe Tailoringmöglichkeiten, Unternehmensprozess muss angepasst werden, wenn RUP sich ändert
Agile Methoden
- Idee: Entbürokratisierung des Prozesses
- beruht auf Agile Manifesto (2001)
- Grundprinzipien: Förderung von Kommunikation/Kollaborisation, Zusammenarbeit mit dem Kunden
- iterativ
- kleine Gruppen arbeiten in großem Raum
- keine großartige Dokumentation
- Kunde immer präsent
- Common Code Ownership: Jedem gehört der Code (d.h. jeder kennt den Code und darf auch selbst alles ändern)
- Kurze Release Zyklen
- Paarprogrammierung
- Standup Meeting (täglich 15 min. im Stehen)
- Testgetriebene Entwicklung (Tests werden vor Methoden geschrieben)
- gemeinsame Strukturverbesserung vor dem Schreiben neuer Methoden
- für große Projekte ungeeignet
Cleanroom Development
- Grundidee: Entwickle Software so, dass sie gleich korrekt ist (frühe Fehlervermeidung)
- großes Projekt wird durch Serie kleiner Projekte ersetzt
- 5-8 Entwickler pro kleinem Projekt
- Anforderungsspezifikation muss hoch formal sein
- Entwickler dürfen Code nicht kompilieren, um ihn zu testen
- Komponenten werden nicht einzeln, sondern zusammen getestet (statistischer Test mit Zufallsdaten, wobei die Soll-Resultate nur vage bekannt sind)
- Fehler werden nur in geringem Umfang toleriert. Zu viele Fehler-->Neuimplementierung
- Vorteil: Systeme sind ungewöhnlich fehlerarm
- Nachteil: Hohe Anforderungen an Entwickler, Systeme mit unklarer Spezifikation können mit diesem Prozess nicht entwickelt werden
- Organisation und Rollenverteilung
- Struktur der Dokumente
- Verfahren für die Anforderungserhebung
- das Vorgehensmodell
- Phasen, Meilsensteine, Prüfkriterien
- Notationen und Sprachen
- Werkzeuge
V-Modell
- Teil des Entwicklungsstandards für IT Systeme des Bundes (1992)
- erweiterte Version: V- Modell XT (2004) XT=Extreme Tailoring
- Meilenstein am Ende jedes Projektabschnitts
- unterstützt verschiedene Entwicklungsarten (inkrementell, komponentenbasiert, agil)
- trennt zwischen Auftraggeber- und Auftragnehmerprojekten
- Jedes Modell definiert Vorgehensbausteine und Projektdurchführungsstrategien
- Projektdurchführungsstrategien ordnen Entscheidungspunkte an
- Produkte müssen beim Erreichen eines Entscheidungspunktes fertig sein
- Vorgehensbaustein fasst Rollen, Produkte und Aktivitäten zusammen, die notwendig zur Lösung der Projektaufgabe sind
- Projekt muss aus mind. 4 Vorgehensbausteinen bestehen (Projektmanagement, Qualitätssicherung, Problem- und Änderungsmanagement, Konfigurationsmanagement)
- ggf. mehr Bausteine durch Tailoring
- Produkt wird durch genau eine Aktivität fertiggestellt
- Produkte hängen voneinander ab
- Rollen sind für Produkte verantwortlich und wirken an diesen mit
- wichtig zu merken: Auf jeder Ebene des Vorgehensmodells gibt es ensprechende Tests (Analyse->Abnahmetest, Grobentwurf->Systemtest, Feinentwurf->Integrationstest, Implementierung->Modultest)
- produziert Overhead bei kleinen Projekten
Unified Process
- auf Objektorientierung abgestimmte Methode durch Jacobsen (1998)
- basiert auf Use Cases
- iterativ: Prototypen in frühen Iterationen
- architekturzentriert
- Besteht aus 4 Phasen (Inception: Verstehen der Anforderungen, Risikobewertung, Use-Case Modellierung, 1. Fassung der Architektur/des Projektplans, Elaboration: Identifkation fehlender Anforderungen, grundlegende Architekturentscheidungen, Construction: Implementierung, Integration + Test, Ergebnis: Betaversion des Systems, Transition: Verbesserung des Systems bis es stabil läuft, Vervollständigung des Systems)
- Arbeitsabläufe, die in unterschiedlicher Intensität während jeder Phase durchgeführt werden: Requirements, Analysis, Design, Implementation, Test (ggf. mehr durch Tailoring, es kommen dann businessorientiertere Arbeitsabläufe hinzu)
- in jeder Phase gibt es mehrere Iterationen
- RUP ist die Ausprägung des UP zu vollwertigem Prozessmodell und wird durch IBM vermarketet
- Arbeitsabläufe werden hier durch UML Aktivitätsdiagramme visualisiert
- Vorteile: gute Dokumentation, guter Support
- Nachteile: geringe Tailoringmöglichkeiten, Unternehmensprozess muss angepasst werden, wenn RUP sich ändert
Agile Methoden
- Idee: Entbürokratisierung des Prozesses
- beruht auf Agile Manifesto (2001)
- Grundprinzipien: Förderung von Kommunikation/Kollaborisation, Zusammenarbeit mit dem Kunden
- iterativ
- kleine Gruppen arbeiten in großem Raum
- keine großartige Dokumentation
- Kunde immer präsent
- Common Code Ownership: Jedem gehört der Code (d.h. jeder kennt den Code und darf auch selbst alles ändern)
- Kurze Release Zyklen
- Paarprogrammierung
- Standup Meeting (täglich 15 min. im Stehen)
- Testgetriebene Entwicklung (Tests werden vor Methoden geschrieben)
- gemeinsame Strukturverbesserung vor dem Schreiben neuer Methoden
- für große Projekte ungeeignet
Cleanroom Development
- Grundidee: Entwickle Software so, dass sie gleich korrekt ist (frühe Fehlervermeidung)
- großes Projekt wird durch Serie kleiner Projekte ersetzt
- 5-8 Entwickler pro kleinem Projekt
- Anforderungsspezifikation muss hoch formal sein
- Entwickler dürfen Code nicht kompilieren, um ihn zu testen
- Komponenten werden nicht einzeln, sondern zusammen getestet (statistischer Test mit Zufallsdaten, wobei die Soll-Resultate nur vage bekannt sind)
- Fehler werden nur in geringem Umfang toleriert. Zu viele Fehler-->Neuimplementierung
- Vorteil: Systeme sind ungewöhnlich fehlerarm
- Nachteil: Hohe Anforderungen an Entwickler, Systeme mit unklarer Spezifikation können mit diesem Prozess nicht entwickelt werden
Welche 3 Schritte gibt es beim Requirements Engineering?
1. Sammeln und Analysieren der Anforderungen mit dem Kunden
2. Strukturierung der Anforderungen (z.B. durch Unterteilen in funktionale, nicht funktionale Anforderungen und Gruppieren gleichgearteter Anforderungen)
3. Prüfung der Anforderungen (z.B. durch Reviews mit Hilfe des linguistischen Ansatzes)
2. Strukturierung der Anforderungen (z.B. durch Unterteilen in funktionale, nicht funktionale Anforderungen und Gruppieren gleichgearteter Anforderungen)
3. Prüfung der Anforderungen (z.B. durch Reviews mit Hilfe des linguistischen Ansatzes)
Was ist eine Architektur und welche Architektursichten gibt es?
Eine Architektur beschreibt die Zerlegung der Software in einzelne Komponenten und deren Beziehungen untereinander. Außerdem werden die Schnittstellen nach Außen definiert. Es gibt folgende Sichten:
Logische Sicht
Klassenmodell als Verfeinerung des UML DIagramms aus der OOA
Ablaufsicht
Sicht auf die Prozesse, deren Kommunikation und Synchronisation untereinander. Wichtig bei verteilten Systemen!
Datensicht
Modellierung des Systems als ER Diagramm
Struktursicht/Systemsicht
Sicht auf das System mit Subsystemen und deren Schnittstellen
Physikalische Sicht
Physikalische Vernetzung der Komponenten (z.B. Vernetzung der Computer, Hardware-Platinen Layout..)
Logische Sicht
Klassenmodell als Verfeinerung des UML DIagramms aus der OOA
Ablaufsicht
Sicht auf die Prozesse, deren Kommunikation und Synchronisation untereinander. Wichtig bei verteilten Systemen!
Datensicht
Modellierung des Systems als ER Diagramm
Struktursicht/Systemsicht
Sicht auf das System mit Subsystemen und deren Schnittstellen
Physikalische Sicht
Physikalische Vernetzung der Komponenten (z.B. Vernetzung der Computer, Hardware-Platinen Layout..)
Wie modelliert man Anforderungen mit Use-Cases?
Als Use Case bezeichnet man eine Sequenz von Aktionen eines Handelnden mit einem System, welche ein bestimmtest Resultat für den Handelnden liefert.
Besonderheiten eines Use Cases
- wenigstens ein Akteur ist am Anwendungsfall beteiligt
- Anwendungsfall wird durch Ereignis (trigger) angestoßen, was der Hauptakteur auslöst
- zielorientiert
- beschreibt alle Interaktionen, die nötig sind, um das Ziel zu erreichen
- endet wenn das Ziel erreich ist oder nicht erreicht werden kann
- muss auch Ausnahme-/ und Sonderfälle spezifizieren
Use Case Diagramme
- bestehen aus Akteur(en), System, Systemgrenzen und Use Cases
- Generalisierungsbeziehung bei Anwendungsfällen und Akteuren
- Benutzt-Beziehung bei Anwendungsfällen: Anwendungsfall wird in entsprechendem Anwendungsfall ausgeführt
- Extends-Beziehung bei Anwendungsfällen: Anwendungsfall wird an einer bestimmten Stelle (Extension Point) eines anderen Anwendungsfalls aufgerufen, wenn eine bestimmte Bedingung erfüllt ist
- es macht Sinn zwischen Hauptfunktionen und Basisfunktionen zu unterscheiden
- ersetzen keine detaillierte Beschreibung der Anwendungsfälle
Notation in strukturierter Form enthält:
- Name und Ziel des Anwendungsfalls
- Vorbedingung
- Nachbedingung
- Nachbedingung im Sonderfall
- Akteure
- Normalablauf
- Sonderfälle
Wie kommt man an die Anwendungsfälle?
- Bestimme alle Akteure, sowie Ein- und Ausgaben
- Lege Systemgrenzen fest
- Identifiziere Anwendungsfälle der Hauptfunktionen
- Strukturiere Anwendungsfälle und Akteure (z.B. in Pakete)
- Beschreibe Normal- und Sonderablauf
- Extrahiere gleiche Interaktionssequenzen und verwende diese als Basisanwendungsfälle
- Prüfe Anwendungsfälle mit dem Klienten
Besonderheiten eines Use Cases
- wenigstens ein Akteur ist am Anwendungsfall beteiligt
- Anwendungsfall wird durch Ereignis (trigger) angestoßen, was der Hauptakteur auslöst
- zielorientiert
- beschreibt alle Interaktionen, die nötig sind, um das Ziel zu erreichen
- endet wenn das Ziel erreich ist oder nicht erreicht werden kann
- muss auch Ausnahme-/ und Sonderfälle spezifizieren
Use Case Diagramme
- bestehen aus Akteur(en), System, Systemgrenzen und Use Cases
- Generalisierungsbeziehung bei Anwendungsfällen und Akteuren
- Benutzt-Beziehung bei Anwendungsfällen: Anwendungsfall wird in entsprechendem Anwendungsfall ausgeführt
- Extends-Beziehung bei Anwendungsfällen: Anwendungsfall wird an einer bestimmten Stelle (Extension Point) eines anderen Anwendungsfalls aufgerufen, wenn eine bestimmte Bedingung erfüllt ist
- es macht Sinn zwischen Hauptfunktionen und Basisfunktionen zu unterscheiden
- ersetzen keine detaillierte Beschreibung der Anwendungsfälle
Notation in strukturierter Form enthält:
- Name und Ziel des Anwendungsfalls
- Vorbedingung
- Nachbedingung
- Nachbedingung im Sonderfall
- Akteure
- Normalablauf
- Sonderfälle
Wie kommt man an die Anwendungsfälle?
- Bestimme alle Akteure, sowie Ein- und Ausgaben
- Lege Systemgrenzen fest
- Identifiziere Anwendungsfälle der Hauptfunktionen
- Strukturiere Anwendungsfälle und Akteure (z.B. in Pakete)
- Beschreibe Normal- und Sonderablauf
- Extrahiere gleiche Interaktionssequenzen und verwende diese als Basisanwendungsfälle
- Prüfe Anwendungsfälle mit dem Klienten
Welche Richtlinien für einen guten Entwurf gibt es?
Modularisierung
- System sollte in sinnvolle,überschaubare Bestandteile (Komponenten) gegliedert werden
- diese bestehen intern wieder aus Modulen
- Identifizierung gemäß Prinzip des Information Hiding
- Modul dient als Schutzhülle für seine Datenstruktur
- Unterteilung nach Nagl: Funktionale Module (z.B. Klasse Math in Java), Datenobjektmodule (Objekte in Java), Datentypmodule (Klassen in Java)
Kopplung und Zusammenhalt
- Beispiel aus dem Alltag: Konzertsaal
- inter-modulare Kopplung (Komplexität der Schnittstellen zwischen den Modulen) sollte gering sein
- intra-modularer Zusammenhalt (Verwandtschaft zwischen Bestandteilen eines Moduls) sollte hoch sein
Information Hiding
- Informationen, die der Programmierer nicht verwenden soll, sollen ihm nicht zugänglich sein (z.B. sollte der Zugriff auf einzelne Attribute nicht direkt, sondern nur über getter und setter Methoden möglich sein)
- Schnittstellen sollen nur das anbieten, was andere Module wirklich benötigen (interne Datenstrukturen bleiben verborgen)
- "Datenschutz" für Module
- Alltagsbeispiel: Kunde möchte Banktransaktion machen (ruft sozusagen die Methode "Transaktion" auf). Die Interne Organisation der Bank interessiert dabei den Kunden nicht. Er erhält immer dasselbe Ergebnis, egal wie die Transaktion intern abläuft.
Open-Closed-Principle
Closed: Modulschnittstellen sollen so gestaltet sein, dass sie ohne Anpassung verwendet werden können (die Schnittstelle ist stabil)
Open: Modul soll sich problemlos erweitern lassen, ohne dass die Schnittstellen sich ändern und somit die Kundenmodule angepasst werden müssten.
Das Open-Closed Principle lässt sich durch Vererbung realisieren.
Trennung von Zuständigkeiten
Interaktion (z.B. durch die Benutzeroberfläche) und Funktionalität sollten getrennt sein.
Objektorientierte Architekturprinzipien
- Abstrakte Klassen (verwenden von abstrakten Methoden, Schablonenmethoden und Basismethoden)
- Generalisierung
- finden von Klassen durch fachliches Begriffsmodell
- Unterscheidung zwischen fachlichen und technischen Klassen
- System sollte in sinnvolle,überschaubare Bestandteile (Komponenten) gegliedert werden
- diese bestehen intern wieder aus Modulen
- Identifizierung gemäß Prinzip des Information Hiding
- Modul dient als Schutzhülle für seine Datenstruktur
- Unterteilung nach Nagl: Funktionale Module (z.B. Klasse Math in Java), Datenobjektmodule (Objekte in Java), Datentypmodule (Klassen in Java)
Kopplung und Zusammenhalt
- Beispiel aus dem Alltag: Konzertsaal
- inter-modulare Kopplung (Komplexität der Schnittstellen zwischen den Modulen) sollte gering sein
- intra-modularer Zusammenhalt (Verwandtschaft zwischen Bestandteilen eines Moduls) sollte hoch sein
Information Hiding
- Informationen, die der Programmierer nicht verwenden soll, sollen ihm nicht zugänglich sein (z.B. sollte der Zugriff auf einzelne Attribute nicht direkt, sondern nur über getter und setter Methoden möglich sein)
- Schnittstellen sollen nur das anbieten, was andere Module wirklich benötigen (interne Datenstrukturen bleiben verborgen)
- "Datenschutz" für Module
- Alltagsbeispiel: Kunde möchte Banktransaktion machen (ruft sozusagen die Methode "Transaktion" auf). Die Interne Organisation der Bank interessiert dabei den Kunden nicht. Er erhält immer dasselbe Ergebnis, egal wie die Transaktion intern abläuft.
Open-Closed-Principle
Closed: Modulschnittstellen sollen so gestaltet sein, dass sie ohne Anpassung verwendet werden können (die Schnittstelle ist stabil)
Open: Modul soll sich problemlos erweitern lassen, ohne dass die Schnittstellen sich ändern und somit die Kundenmodule angepasst werden müssten.
Das Open-Closed Principle lässt sich durch Vererbung realisieren.
Trennung von Zuständigkeiten
Interaktion (z.B. durch die Benutzeroberfläche) und Funktionalität sollten getrennt sein.
Objektorientierte Architekturprinzipien
- Abstrakte Klassen (verwenden von abstrakten Methoden, Schablonenmethoden und Basismethoden)
- Generalisierung
- finden von Klassen durch fachliches Begriffsmodell
- Unterscheidung zwischen fachlichen und technischen Klassen
Was sind PERT-Charts und welche Informationen erhält man aus ihnen?
PERT Charts sind Netzpläne, die das Projektmanagement bei der zeitlichen Planung von Aktivitäten unterstützen. Sie sehen wie folgt aus:
Mit Hilfe von Ihnen lassen sich kritische Arbeitspakete und kritische Pfade finden. Bei kritischen Arbeitspaketen gibt es keinen Puffer zwischen frühstem Start- und Endzeitpunkt und spätestem Start- und Endzeitpunkt. Kritische Pfade sind Aneinanderreihungen von kritischen Arbeitspaketen vom Startzustand bis zum Endzustand.
| frühster Startzeitpunkt | Dauer | frühster Endzeitpunkt |
| Bezeichner | ||
| spätester Startzeitpunkt | spätester Endzeitpunkt |
Mit Hilfe von Ihnen lassen sich kritische Arbeitspakete und kritische Pfade finden. Bei kritischen Arbeitspaketen gibt es keinen Puffer zwischen frühstem Start- und Endzeitpunkt und spätestem Start- und Endzeitpunkt. Kritische Pfade sind Aneinanderreihungen von kritischen Arbeitspaketen vom Startzustand bis zum Endzustand.
Welche linguistischen Regeln gibt es bei der Anforderungsspezifikation?
Tilgung (etwas wichtiges wird weggelassen)
unvollständig spezifizierte Prozesswörter
- Passiv statt Aktiv
- Hilfsverben statt Vollverben
unvollständige Vergleiche/Steigerungen
- "Sonstige" Bibliothekskunden
- "Leicht" änderbar
Implizite Annahmen
-Bei Überschreitung der Leihfrist (Leihfrist nicht genau spezifiziert)
Generalisierung (es wird verallgemeinert)
- Universalquantoren
- unvollständig spezifizierte Bedingungen
- Substantive ohne Bezugsindex
Verzerrung (Verfälschung der Realität)
Nominalisierung
Ein komplexer Prozess wird als Substantiv beschrieben (z.B. "das Ausdrucken", "die Reservierung", "die Rückgabe"...)
Konkretes Beispiel: Bei der Rückgabe eines Buches soll eine Benachrichtigung verschickt werden (hier sollte der doch komplexere Prozess der Rückgabe genauer beschrieben werden)
unvollständig spezifizierte Prozesswörter
- Passiv statt Aktiv
- Hilfsverben statt Vollverben
unvollständige Vergleiche/Steigerungen
- "Sonstige" Bibliothekskunden
- "Leicht" änderbar
Implizite Annahmen
-Bei Überschreitung der Leihfrist (Leihfrist nicht genau spezifiziert)
Generalisierung (es wird verallgemeinert)
- Universalquantoren
- unvollständig spezifizierte Bedingungen
- Substantive ohne Bezugsindex
Verzerrung (Verfälschung der Realität)
Nominalisierung
Ein komplexer Prozess wird als Substantiv beschrieben (z.B. "das Ausdrucken", "die Reservierung", "die Rückgabe"...)
Konkretes Beispiel: Bei der Rückgabe eines Buches soll eine Benachrichtigung verschickt werden (hier sollte der doch komplexere Prozess der Rückgabe genauer beschrieben werden)
Welche Qualitäten bezogen auf Software gibt es?
Als Antwort auf diese Frage hat Barry Boehm einen Qualitätenbaum definiert, der zunächst gron zwischen Produkt- und Prozessqualität unterscheidet. Prozessqualität lässt sich z.B. weiter untergliedern in Planungssicherheit und innere Prozessqualität wie z.B. das Projektklima. Hier haben also auch "weichere" Faktoren einen Einfluss. Produktqualität unterscheidet zwischen Wartbarkeit und Brauchbarkeit. Unterqualitäten der Wartbarkeit sind Änderbarkeit, Prüfbarkeit und Portabilität. Die Qualität Brauchbarkeit setzt sich wiederum aus Zuverlässigkeit, Nützlichkeit und Bedienbarkeit zusammen. Nicht alle dieser Qualitäten lassen sich durch Metriken messen.
Was ist ein Prozessmodell und welche Prozessphasen gibt es allgemein?
Vorgehensmodelle eignen sich nur dazu, den Entwicklern Hinweise zu geben, welche Tätigkeit als nächste auszuführen ist. Prozessmodelle machen aber zusätzliche Aussagen über die personelle Organisation, die Gliederung der Dokumentation und die Verantwortlichkeiten für Aktivitäten und Dokumente. Außerdem werden Angaben zu Werkzeugen und Methoden gemacht.
Wie funktioniert das Spiralmodell?
Das Spiralmodell ist ein inkrementelles,generisches Vorgehensmodell, dass je nach Risiko des Projektes zu einem spezifischen Modell ausgeprägt werden kann. Der Zyklus (die Spirale) des Modells kann wie folgt beschrieben werden:
Wiederhole
1. Suche alle Risiken, die das Projekt bedrohen. Wenn es keine Risiken mehr gibt, ist das Projekt abgeschlossen.
2. Identifiziere das größte Risiko
3. Versuche das Risiko zu beseitigen. Falls dies nicht möglich ist, ist das Projekt gescheitert
I.A. versucht man die Risiken durch frühes Prototyping auszuräumen. Man erkennt also in der Regel sehr schnell, woran das Projekt scheitern könnte und nicht erst beim Betrieb des Systems (wie es beim Wasserfallmodell der Fall sein könnte).
Die Spirale ist in 4 Quadranten eingeteilt, die iterativ durchlaufen werden:
1. Ziele, Randbedingungen ermitteln
2. Risikoanalyse (Prototypenbau)
3. Entwickeln und Prüfen des Teilproduktes (Im Prinzip werden hier alle Teilschritte des Softwareentwicklungszyklus durchlaufen)
4. Planung der nächsten Phase (Spezifikationsplan, Entwurfsplan, Testplan)
Da das Spiralmodell ein genrisches Modell ist, kann es z.B. auch zum Wasserfallmodell ausgeprägt werden, wenn die Risiken Scheitern der Analyse, Scheitern des Entwurfs... sind
Wiederhole
1. Suche alle Risiken, die das Projekt bedrohen. Wenn es keine Risiken mehr gibt, ist das Projekt abgeschlossen.
2. Identifiziere das größte Risiko
3. Versuche das Risiko zu beseitigen. Falls dies nicht möglich ist, ist das Projekt gescheitert
I.A. versucht man die Risiken durch frühes Prototyping auszuräumen. Man erkennt also in der Regel sehr schnell, woran das Projekt scheitern könnte und nicht erst beim Betrieb des Systems (wie es beim Wasserfallmodell der Fall sein könnte).
Die Spirale ist in 4 Quadranten eingeteilt, die iterativ durchlaufen werden:
1. Ziele, Randbedingungen ermitteln
2. Risikoanalyse (Prototypenbau)
3. Entwickeln und Prüfen des Teilproduktes (Im Prinzip werden hier alle Teilschritte des Softwareentwicklungszyklus durchlaufen)
4. Planung der nächsten Phase (Spezifikationsplan, Entwurfsplan, Testplan)
Da das Spiralmodell ein genrisches Modell ist, kann es z.B. auch zum Wasserfallmodell ausgeprägt werden, wenn die Risiken Scheitern der Analyse, Scheitern des Entwurfs... sind
Welche Eigenschaften sollte ein Testfall erfüllen?
- repräsentativ sein (d.h. stellvertretend für viele Testfälle stehen)
- fehlerintensiv sein (d.h. er sollte nach der Fehlertheorie eine hohe Wahrscheinlichkeit haben, Fehler zu finden)
- redundanzarm sein (d.h. er sollte nicht das prüfen, was andere Testfälle auch schon prüfen. Dies lässt sich aber manchmal leider nicht vermeiden)
- fehlerintensiv sein (d.h. er sollte nach der Fehlertheorie eine hohe Wahrscheinlichkeit haben, Fehler zu finden)
- redundanzarm sein (d.h. er sollte nicht das prüfen, was andere Testfälle auch schon prüfen. Dies lässt sich aber manchmal leider nicht vermeiden)
Welche Rollen beim Review gibt es?
Moderator
- lädt zum Review ein
- moderiert das Review und vermittelt zwischen den Parteien
- berichtet dem Management
Schriftführer
- protokolliert die Ergebnisse des Reviews
Autor
- stellt den Prüfling zur Verfügung
- rechtfertigt sich nicht
Gutachter
- begutachten und bewerten den Prüfling
- geben Empfehlung für das Management
Manager
- nimmt nicht am Review teil
- entscheidet auf Grundlage der Empfehlung der Gutachter, ob der Prüfling akzeptiert wird oder nicht
- lädt zum Review ein
- moderiert das Review und vermittelt zwischen den Parteien
- berichtet dem Management
Schriftführer
- protokolliert die Ergebnisse des Reviews
Autor
- stellt den Prüfling zur Verfügung
- rechtfertigt sich nicht
Gutachter
- begutachten und bewerten den Prüfling
- geben Empfehlung für das Management
Manager
- nimmt nicht am Review teil
- entscheidet auf Grundlage der Empfehlung der Gutachter, ob der Prüfling akzeptiert wird oder nicht
Wie lassen sich Metriken einteilen?
Im Allgemeinen in Produkt-/ und Prozessmetriken. Man kann sie auch in die Kategorien Kostenmetriken (z.B. COCOMO), Fehlermetriken (liefern z.B. Aussagen über die Zahl der erwarteten Fehler), Volumens- und Umfangsmetriken und Qualitätsmetriken einteilen.
Welche Stellschrauben gibt es beim Controlling?
Im Projektmanagement gibt es allgemein das magische Dreieck mit den Eckenbeschriftungen Zeit, Geld und Qualität. Zieht man an einer dieser Ecken (erhöht man z.B. die Entwicklungszeit), so hat das gleichzeitig mehr Kosten zur Folge. Man kann also nicht einen Parameter erhöhen, ohne gleichzeitig die anderen zu variieren. Zeit, Kosten, Qualität, evtl. Personal sind also die Stellschrauben beim Controlling.
Welche Möglichkeiten haben wir, wenn wir nicht im Zeitplan sind?
- die Qualität reduzieren (auf Realisierung von Anforderungen verzichten, nicht mehr so intensiv testen...)
- schneller entwickeln
- Entwickler müssen länger arbeiten
- mehr Entwickler in das Projekt stecken
- zur Veranschaulichung kann man sich wieder das magische Dreieck des Projektmanagements anschauen
- schneller entwickeln
- Entwickler müssen länger arbeiten
- mehr Entwickler in das Projekt stecken
- zur Veranschaulichung kann man sich wieder das magische Dreieck des Projektmanagements anschauen
Was ist das Model-View-Controller Pattern?
Hierbei handelt es sich um ein Architekturpattern, welches oft bei der Entwicklung von Projekten mit GUI eingesetzt wird. Es besteht aus den Komponenten Model, View und Controller. Die View stellt das Benutzerfrontend dar, welches auf Benutzereingaben reagiert und diese an den Controller delegiert. Dieser kommuniziert dann mit dem Backend (dem Model) und schickt die Ergebnisse zurück an die View, welche dadurch aktualisiert wird.
Was sind Rahmenwerke und welche Arten von Rahmenwerken gibt es?
geschlossen
- Rahmenwerk kann ohne Kenntnis seiner Interna verwendet werden
- Entwickler erzeugt spezielle Objekte der Rahmenwerksklasse und konfiguriert diese
offen
- Spezialisierung der abstrakten Klassen der Hotspots
- erfordert Wissen darüber, welche Methoden redefiniert werden müssen
- Rahmenwerk stellt Beispielanwendungen bereit, die der Benutzer für seine eigene Implementierung verwenden kann
- Rahmenwerk kann ohne Kenntnis seiner Interna verwendet werden
- Entwickler erzeugt spezielle Objekte der Rahmenwerksklasse und konfiguriert diese
offen
- Spezialisierung der abstrakten Klassen der Hotspots
- erfordert Wissen darüber, welche Methoden redefiniert werden müssen
- Rahmenwerk stellt Beispielanwendungen bereit, die der Benutzer für seine eigene Implementierung verwenden kann
Was ist das modellhafte an Metriken?
Sie besitzen die typischen Modellmerkmale:
Abbildungsmerkmal: Zu jeder Metrik gibt es eine reale Größe/ein real existierendes Artefakt in der Softwareentwicklung
Verkürzungsmerkmal: Die Metrik gibt nicht alle Eigenschaften der Originalgröße wieder, sondern verkürzt auf das Wesentliche
Pragmatisches Merkmal: Die Metrik ersetzt unter umständen das Original (z.B. arbeitet das Management nur mit der Metrik)
Abbildungsmerkmal: Zu jeder Metrik gibt es eine reale Größe/ein real existierendes Artefakt in der Softwareentwicklung
Verkürzungsmerkmal: Die Metrik gibt nicht alle Eigenschaften der Originalgröße wieder, sondern verkürzt auf das Wesentliche
Pragmatisches Merkmal: Die Metrik ersetzt unter umständen das Original (z.B. arbeitet das Management nur mit der Metrik)
Welche Entwurfsmuster gibt es?
Entwurfsmuster sind Lösungsschablonen für wiederkehrende Entwurfsprobleme im Grob- oder Feinentwurf. Sie lassen sich grob in erzeugende Muster, strukturelle Muster und Verhaltensmuster unterteilen. 23 dieser Patterns sind in Erich Gammas Buch Design Patterns - Elements of Reusable Object-Oriented Software beschrieben. Die Patterns heißen auch Gang of Four Patterns, bezugnehmend auf Gamma und seine 3 Coautoren. Hier eine kleine Auswahl der wichtigsten Patterns:
Singleton
Es soll nur ein Objekt einer Klasse erstellt werden können. Dazu wird einfach in der Methode instanceOf() überprüft, ob schon ein Objekt der Klasse exisitiert. Wenn ja, wird das alte Objekt zurückgeliefert, wenn nein, wird das neue Objekt erstellt.
Strategy
Verwandte Klassen unterscheiden sich dadurch, dass sie gleiche Aufgaben durch verschiedene Algorithmen lösen. Anstatt das Problem durch direkte Vererbung zu lösen, wird eine Klasse StrategyContext erstellt, die gemeinsame Operationen definiert. Die Signaturen der unterschiedlich zu implementierenden Operationen werden in der abstrakten Klasse Strategy zusammengefasst. Die Subklasse ConcreteStrategy überschreibt dann diese Methode.
Beispiel: Für eine Auftragsabwicklung braucht man eine Steuerberechnung, die länderabhängig ist. Anstatt die Subklasse D_Steuerrechner, A_Steuerrechner und CH_Steuerrechner einzuführen, definiert man einfach eine Methode berechneSteuer() und einen Steuerrechner als private Attribut. Dieser abstrakte Steuerrechner hat dann als Subklassen CH_Steuerrechner... Auf diese Weise trennt man Auftragsabwicklung und Steuerberechnung und hat innerhalb der Klassen einen besseren Zusammenhalt.
Decorator
Alternative zur Unterklassenbildung, um eine Klasse um zusätzliche Funktionalität zu erweitern. Der Dekorierer erbt von der zu dekorierenden Klasse und hat die gleiche Schnittstelle wie diese. Die Subklassen des Dekorierers sind konkrete Dekorierer und können zusätzliche Operationen oder Zustände bereitstellen. Der User merkt bei Verwendung der Klasse meist nicht, dass ein Dekorierer vorgeschaltet ist.
Fascade
Eine Klasse soll nur bestimmte Operationen einer anderen Klasse aufrufen können. Dies wird realisiert, indem man in einer Fassadenklasse nur die entsprechenden Methoden definiert, die sichtbar sein sollen. Diese delegieren den Aufruf dann an die Methoden der eigentlichen Klasse.
Adapter
Der Adapter wird eingesetzt, wenn man eine Methode verwenden möchte, deren Signatur nicht passt. Man schreibt sich eine Adapterklasse mit passender Signatur, die an die Klasse mit unpassender Signatur delegiert. Dabei werden z.B. bestimmte Parameter der nicht passenden Klasse mit Konstanten vorbelegt.
Observer
Mehrere Objekte sollen ein Objekt beobachten können und sollen bei Änderung informiert werden. Das beobachtete Objekt soll die genau Implementierung der Observer nicht kennen, lediglich festgelegte Schnittstellenmethoden.
Die Observer ergeben von der Oberklasse Observer oder implementieren ein entsprechendes Interface. Die beobachtete Klasse implementiert das Interface Observable, welches Methoden zum Benachrichtigen der Observer bereitstellt. Ändert sich das Observable ruft es notifyObservers() auf, welche ihrerseits die Methode getState() des Observables (über Schnittstelle definiert) aufrufen.
State
Für ein Objekt soll das Verhalten zustandsabhängig modelliert werden (z.B. sind die Zustandsübergänge in einem StateChart modelliert). Man möchte ständige if-Abfragen vermeiden.
Man hat eine Klasse StateContext, die sich zustandsabhängig verhalten soll. Diese kennt ihren State (abstrakte Klasse). Die State-Klasse besitzt alle Klassen des Zustandsautomaten als Unterklassen. Diese Unterklassen bieten die Methoden an, die in diesem State zugreifbar sind. Die Klasse StateContext delegiert die Methodenaufrufe an die State Klassen (also sagt so etwas wie this.state.doSomething())
Man bekommt bei diesem Pattern eine relativ saubere Struktur und benötigt wenig if-Abfragen. Allerdings produziert man evtl. viel redundanten Code.
Factory Method
Eine Klasse soll Objekte erzeugen, möchte diese aber nicht kennen und delegiert die Erzeugung der Objekte (und die Bestimmung welche Objekte erzeugt werden sollen) an Unterklassen.
Am Muster sind 4 Klassen beteiligt: Produkt, konkretes Produkt, Abstrakte Fabrik und konkrete Fabrik.
Beispielsweise möchte man Eis erzeugen, man weiß aber nicht genau welches, bzw. überlässt dies der Unterklasse. Man sagt dann Eisfabrik.erzeugeEis() und erhält dann ein Objekt des abstrakten Produkts Eis zurück. Die Eisfabrik könnte nun selbst entscheiden wie sie reagiert, also welches Eis sie erzeugt (z.B. zufällig Erdbeer oder Schokolade). Sie ruft dann konkret die Konstruktoren dieser konkreten Produkte auf und liefert das Eisobjekt zurück.
Die Aufruferklasse wird durch das Pattern von der Implementierung konkreter Produktklassen entkoppelt.
Template Method
Mehrere Algorithmen sind sich sehr ähnlich, unterscheiden sich aber durch einzelne Methoden.
Man implementiert eine abstrakte Oberklasse Algorithmus, die die Schablonenmethode apply() bereitstellt und die Gemeinsamkeiten zusammenfasst. In dieser Methode sind aber abstrakte Methoden eingebaut, die erst in den Unterklassen realisiert werden. So brauchen die Unterklassen nicht noch extra (redundant) den gemeinsamen Code implementieren.
Singleton
Es soll nur ein Objekt einer Klasse erstellt werden können. Dazu wird einfach in der Methode instanceOf() überprüft, ob schon ein Objekt der Klasse exisitiert. Wenn ja, wird das alte Objekt zurückgeliefert, wenn nein, wird das neue Objekt erstellt.
Strategy
Verwandte Klassen unterscheiden sich dadurch, dass sie gleiche Aufgaben durch verschiedene Algorithmen lösen. Anstatt das Problem durch direkte Vererbung zu lösen, wird eine Klasse StrategyContext erstellt, die gemeinsame Operationen definiert. Die Signaturen der unterschiedlich zu implementierenden Operationen werden in der abstrakten Klasse Strategy zusammengefasst. Die Subklasse ConcreteStrategy überschreibt dann diese Methode.
Beispiel: Für eine Auftragsabwicklung braucht man eine Steuerberechnung, die länderabhängig ist. Anstatt die Subklasse D_Steuerrechner, A_Steuerrechner und CH_Steuerrechner einzuführen, definiert man einfach eine Methode berechneSteuer() und einen Steuerrechner als private Attribut. Dieser abstrakte Steuerrechner hat dann als Subklassen CH_Steuerrechner... Auf diese Weise trennt man Auftragsabwicklung und Steuerberechnung und hat innerhalb der Klassen einen besseren Zusammenhalt.
Decorator
Alternative zur Unterklassenbildung, um eine Klasse um zusätzliche Funktionalität zu erweitern. Der Dekorierer erbt von der zu dekorierenden Klasse und hat die gleiche Schnittstelle wie diese. Die Subklassen des Dekorierers sind konkrete Dekorierer und können zusätzliche Operationen oder Zustände bereitstellen. Der User merkt bei Verwendung der Klasse meist nicht, dass ein Dekorierer vorgeschaltet ist.
Fascade
Eine Klasse soll nur bestimmte Operationen einer anderen Klasse aufrufen können. Dies wird realisiert, indem man in einer Fassadenklasse nur die entsprechenden Methoden definiert, die sichtbar sein sollen. Diese delegieren den Aufruf dann an die Methoden der eigentlichen Klasse.
Adapter
Der Adapter wird eingesetzt, wenn man eine Methode verwenden möchte, deren Signatur nicht passt. Man schreibt sich eine Adapterklasse mit passender Signatur, die an die Klasse mit unpassender Signatur delegiert. Dabei werden z.B. bestimmte Parameter der nicht passenden Klasse mit Konstanten vorbelegt.
Observer
Mehrere Objekte sollen ein Objekt beobachten können und sollen bei Änderung informiert werden. Das beobachtete Objekt soll die genau Implementierung der Observer nicht kennen, lediglich festgelegte Schnittstellenmethoden.
Die Observer ergeben von der Oberklasse Observer oder implementieren ein entsprechendes Interface. Die beobachtete Klasse implementiert das Interface Observable, welches Methoden zum Benachrichtigen der Observer bereitstellt. Ändert sich das Observable ruft es notifyObservers() auf, welche ihrerseits die Methode getState() des Observables (über Schnittstelle definiert) aufrufen.
State
Für ein Objekt soll das Verhalten zustandsabhängig modelliert werden (z.B. sind die Zustandsübergänge in einem StateChart modelliert). Man möchte ständige if-Abfragen vermeiden.
Man hat eine Klasse StateContext, die sich zustandsabhängig verhalten soll. Diese kennt ihren State (abstrakte Klasse). Die State-Klasse besitzt alle Klassen des Zustandsautomaten als Unterklassen. Diese Unterklassen bieten die Methoden an, die in diesem State zugreifbar sind. Die Klasse StateContext delegiert die Methodenaufrufe an die State Klassen (also sagt so etwas wie this.state.doSomething())
Man bekommt bei diesem Pattern eine relativ saubere Struktur und benötigt wenig if-Abfragen. Allerdings produziert man evtl. viel redundanten Code.
Factory Method
Eine Klasse soll Objekte erzeugen, möchte diese aber nicht kennen und delegiert die Erzeugung der Objekte (und die Bestimmung welche Objekte erzeugt werden sollen) an Unterklassen.
Am Muster sind 4 Klassen beteiligt: Produkt, konkretes Produkt, Abstrakte Fabrik und konkrete Fabrik.
Beispielsweise möchte man Eis erzeugen, man weiß aber nicht genau welches, bzw. überlässt dies der Unterklasse. Man sagt dann Eisfabrik.erzeugeEis() und erhält dann ein Objekt des abstrakten Produkts Eis zurück. Die Eisfabrik könnte nun selbst entscheiden wie sie reagiert, also welches Eis sie erzeugt (z.B. zufällig Erdbeer oder Schokolade). Sie ruft dann konkret die Konstruktoren dieser konkreten Produkte auf und liefert das Eisobjekt zurück.
Die Aufruferklasse wird durch das Pattern von der Implementierung konkreter Produktklassen entkoppelt.
Template Method
Mehrere Algorithmen sind sich sehr ähnlich, unterscheiden sich aber durch einzelne Methoden.
Man implementiert eine abstrakte Oberklasse Algorithmus, die die Schablonenmethode apply() bereitstellt und die Gemeinsamkeiten zusammenfasst. In dieser Methode sind aber abstrakte Methoden eingebaut, die erst in den Unterklassen realisiert werden. So brauchen die Unterklassen nicht noch extra (redundant) den gemeinsamen Code implementieren.
Was ist Reengineering und Reverse Engineering?
Reverse Engineering
Wiederherstellung der Anforderungen aus gegebenen Dokumenten (Code, Entwurf,...)
Reengineering
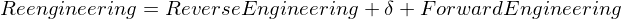
Aufgrund von Unzufriedenheit mit einem alten System, stellt man die Anforderungen durch Reverse Engineering wieder her und durchläuft dann den standardmäßigen Softwareentwicklungsprozess, um eine bessere Architektur und somit ein besseres System zu erhalten.
Wiederherstellung der Anforderungen aus gegebenen Dokumenten (Code, Entwurf,...)
Reengineering
Aufgrund von Unzufriedenheit mit einem alten System, stellt man die Anforderungen durch Reverse Engineering wieder her und durchläuft dann den standardmäßigen Softwareentwicklungsprozess, um eine bessere Architektur und somit ein besseres System zu erhalten.
Was ist Refactoring?
Refactoring ist Reengineering im Kleinen. Man möchte die Wartbarkeit des Systems erhöhen, die Funktionalität des Systems jedoch unverändert lassen. Dazu baut man die Architektur an der gewünschten Stelle um und testet, um sicherzustellen, dass die Veränderungen keine Fehler produziert haben.
 Testfallmenge der Programme ist gleich
Testfallmenge der Programme ist gleich Kein Fehler beim Testen des Systems
Kein Fehler beim Testen des SystemsWelche Maßnahmen zur Qualitätssicherung gibt es?
Konstruktive Maßnahmen
Diese Maßnahmen sorgen dafür, dass das Softwareprodukt bzw. der Softwareentwicklungsprozess bestimmten Standards genügt oder verbessert wird. Ziel ist das Vermeiden von Fehlern. Dies kann z.B. durch Methoden, Werkzeuge oder Standards geschehen. Typische Beispiele für konstruktive Maßnahmen sind das CMMI zur Messung des Reifegrades von Softwareentwicklungsprozessen oder das Configuration and Change Management als Methode zur Qualitätssicherung.
Analytische Maßnahmen
Diese Maßnahmen messen das existierende Qualitätsniveau und werden erst durch gewisse konstruktive Maßnahmen ermöglicht. Ziel ist das Entdecken von Fehlern. So könnten Modultest z.B. nicht ohne eine vorhergehende Modularisierung durchgeführt werden. Analytische Maßnahmen lassen sich wiederum in statische und dynamische Maßnahmen unterteilen. Statische Maßnahmen sind z.B. Reviews oder die linguistische Analyse der Anforderungsspezifikation. Dynamische Maßnahmen sind das Testen durch Black- und Whiteboxtests sowie objektorientierte Testmethoden wie der zustandsbasierte Klassentest. Außerdem können Softwaremetriken erstellt werden, die als Indikator z.B. für die Qualität des Codes dienen.
Diese Maßnahmen sorgen dafür, dass das Softwareprodukt bzw. der Softwareentwicklungsprozess bestimmten Standards genügt oder verbessert wird. Ziel ist das Vermeiden von Fehlern. Dies kann z.B. durch Methoden, Werkzeuge oder Standards geschehen. Typische Beispiele für konstruktive Maßnahmen sind das CMMI zur Messung des Reifegrades von Softwareentwicklungsprozessen oder das Configuration and Change Management als Methode zur Qualitätssicherung.
Analytische Maßnahmen
Diese Maßnahmen messen das existierende Qualitätsniveau und werden erst durch gewisse konstruktive Maßnahmen ermöglicht. Ziel ist das Entdecken von Fehlern. So könnten Modultest z.B. nicht ohne eine vorhergehende Modularisierung durchgeführt werden. Analytische Maßnahmen lassen sich wiederum in statische und dynamische Maßnahmen unterteilen. Statische Maßnahmen sind z.B. Reviews oder die linguistische Analyse der Anforderungsspezifikation. Dynamische Maßnahmen sind das Testen durch Black- und Whiteboxtests sowie objektorientierte Testmethoden wie der zustandsbasierte Klassentest. Außerdem können Softwaremetriken erstellt werden, die als Indikator z.B. für die Qualität des Codes dienen.
Welche Testauswahlkriterien gibt es?
Beim Whiteboxtest schaut man sich den Programmablaufplan an und definiert verschiedene Überdeckungskriterien wie Anweisungsüberdeckung, Kantenüberdeckung oder Pfadüberdeckung. Anhand dieser können die Testfälle ausgewählt werden. Beim Blackboxtest sollte man Äquivalenzklassen bilden. Die Testfälle sollten dann diese Äquivalenzklassen und Randbereiche bestimmter Wertebereiche abdecken.
Flashcard set info:
Author: ChristianK
Main topic: Informatik
Topic: Softwaretechnik
School / Univ.: RWTH Aachen
City: Aachen
Published: 24.04.2010
Card tags:
All cards (64)
no tags
