

Wofür braucht man DBMS?
Bei der Informationsverarbeitung ohne DBMS treten Probleme auf:
- Redundanz und Inkonsistenz (Herr Herrlein wird Herr Fiebig). Grund: Information für verschiedene Gruppen interessant, daher mehrfach gespeichert -> Redundanz, bei Änderungen Inkonsistenz
- Beschränkte Zugriffsmöglichkeiten (alle Eigenschaften von Herrn Müller lesen müssen, nur um seine Telefonnummer zu sehen)
- Probleme beim Mehrbenutzerbetrieb (A überschreibt Änderungen von B)
- Verlust von Daten (Dateibackup reicht nicht)
- Integritätsverletzungen (Eigenschaften sicherstellen)
- Sicherheitsprobleme (Jeder darf jedes Gehalt sehen?)
- Hohe Entwicklungskosten für Anwendungsprogramme (für jede Anwendung das Rad neu erfinden)
Tags:
Quelle: DB 2007 Kapitel 1 von Prof. Staab / Dr, Sizov
Quelle: DB 2007 Kapitel 1 von Prof. Staab / Dr, Sizov
Wie ist das mit der Datenabstraktion?
Man unterscheidet drei Abstraktionsebenen im DBMS
Es der Datenabstraktion folgt Datenunabhängigkeit: Veränderungen an der physischen Ebene ändern nichts an der logischen (physische DU). Die logische Datenunabhängigkeit kann zum Teil durch Sichten erreicht werden.
- Auf der physischen Ebene wird beschrieben, wie diese Daten physisch gespeichert werden.
- Auf der logischen Ebene beschreiben wir in Schemata, welche Daten gespeichert werden.
- Sichten stellen Teilmengen der Daten zur Verfügung, die auf die Bedürfnisse unterschiedlicher Benutzergruppen zugeschnitten sind.
Es der Datenabstraktion folgt Datenunabhängigkeit: Veränderungen an der physischen Ebene ändern nichts an der logischen (physische DU). Die logische Datenunabhängigkeit kann zum Teil durch Sichten erreicht werden.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 1 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 1 von Prof. Staab und Dr. Sizov
Wie geht man beim Datenbankenwurf vor?
1. Anforderungsanalyse: Den Ausschnitt der Welt verstehen: Welche Informationen liegen vor, wie werden sie verarbeitet? -> Spezifikation
2. Konzeptueller Entwurf: ER-Schema aufstellen
3. Implementationsentwurf: Relationen herleiten:
4. Physischer Entwurf: Physische Ebene optimieren, Kenntnisse des OS und der Hardware nötig
2. Konzeptueller Entwurf: ER-Schema aufstellen
3. Implementationsentwurf: Relationen herleiten:
- Für jede Entität eine Relation erstellen
- Für jede Beziehung eine Relation aus den Attributen der Beziehung und den Schlüsselattributen der zugeordneten Entitäten (Fremdschlüssel)
- Verfeinern: 1:1 Beziehungen mit gleichem Schlüssel zusammenfassen etc.
- Relationen normalisieren
4. Physischer Entwurf: Physische Ebene optimieren, Kenntnisse des OS und der Hardware nötig
Tags: entwurf
Quelle:
Quelle:
Wie sieht so ein ER-Diagramm aus?
 Ein Entity Relationship-Schema wird am besten als Diagramm modelliert.
Ein Entity Relationship-Schema wird am besten als Diagramm modelliert.Entities sind wohlunterscheidbare physische oder gedankliche Konzepte der zu modellierenden Welt, grafisch als Rechtecke dargestellt mit Namen drin.
Relationships sind Beziehungen, die zu Beziehungstypen abstrahiert werden. Als Raute repräsentiert, die mit den beteiligten Entities über ungerichtete Kanten verbunden sind.
Beide können mit Attributen charakterisiert werden, welche in ovale Kreise geschrieben und dem Ziel zugeordnet werden.
Es gibt auch Rollen, Multiplizitäten (Konsistenzbedingungen!), Generalisierung und Aggregation. Ausserdem: Schwache Entities.
Wie kann man relationale Schemata verfeinern? Was sind Anomalien?
Generell können Relationen, die den gleichen Schlüssel beinhalten, manchmal zusammengefasst werden.
1:1 Relationen können problemlos zusammengefasst werden. Allerdings sollten dabei Null-Werte vermieden werden (Jeder Professor hat ein Dienstzimmer, aber nicht jeder Raum ist ein Dienstzimmer).
Wenn 1:N oder N:1-Relationen zusammengefasst werden, ist ein Faktum mehrfach in der Relation enthalten. Durch diese Redundanz entsteht die Update-Anomalie: Wenn ein Wert zu einem Schlüssel geändert wird, ist der Schlüssel kein Schlüssel mehr (Inkonsistenz!).
1:1 Relationen können problemlos zusammengefasst werden. Allerdings sollten dabei Null-Werte vermieden werden (Jeder Professor hat ein Dienstzimmer, aber nicht jeder Raum ist ein Dienstzimmer).
Wenn 1:N oder N:1-Relationen zusammengefasst werden, ist ein Faktum mehrfach in der Relation enthalten. Durch diese Redundanz entsteht die Update-Anomalie: Wenn ein Wert zu einem Schlüssel geändert wird, ist der Schlüssel kein Schlüssel mehr (Inkonsistenz!).

Welche Anomalien können auftreten?
Szenario: Zwei Relationen A und B mit 1:N-Beziehung wurden zusammengefasst.
- Die Update-Anomalie: Was passiert, wenn ein Wert für ein Element aus A sich ändert? Alle Tupel, die diese Entität betreffen, müssen angepasst werden.
- Die Lösch-Anomalie: Wenn die letzte Information aus A zu einer Entität gelöscht wird, gehen auch die Informationen aus B verloren.
- Die Einfüge-Anomalie: Wenn ein Element aus A keine Korrespondenz in B hat, kann man sie nicht einfügen.
Was ist die relationale Algebra?
Mit der relationalen Algebra kann man Daten aus relationalen Modellen extrahieren, es ist also eine Abfragesprache.
Sie kennt u. a. die folgenden Operatoren:
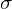 (Selektion),
(Selektion), 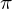 (Projektion),
(Projektion),  (Kreuzprodukt),
(Kreuzprodukt), 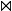 (Join),
(Join), 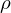 (Umbenennung), - (Mengendifferenz),
(Umbenennung), - (Mengendifferenz),  (Division),
(Division),  (Vereinigung),
(Vereinigung),  (Mengenschnitt) und diverse Derivate des Join-Symbols für die Join-Arten.
(Mengenschnitt) und diverse Derivate des Join-Symbols für die Join-Arten.
Ein (natürlicher) Join ist ein Kreuzprodukt, bei dem nur die Tupel enthalten sind, deren Attribute in gleichbenannten Spalten identisch sind.
Sie kennt u. a. die folgenden Operatoren:
(Selektion), (Projektion), (Kreuzprodukt), (Join), (Umbenennung), - (Mengendifferenz), (Division), (Vereinigung), (Mengenschnitt) und diverse Derivate des Join-Symbols für die Join-Arten.Ein (natürlicher) Join ist ein Kreuzprodukt, bei dem nur die Tupel enthalten sind, deren Attribute in gleichbenannten Spalten identisch sind.
Was ist SQL?
Die Structured Query Language (SQL) ist eine standardisierte Datendefinitions- (DDL), Datenmanipulations- (DML) und Abfragesprache (also mehr als nur eine Query Language, aber gut).
Von der ANSI standardisiert, etwa SQL99 oder SQL3. Es gibt objektrelationale Erweiterungen.
SQL-Anfragen können direkt in die relationale Algebra überführt werden.
Besonderheiten sind: Mengen (union, intersect, minus), Gruppierung samt Aggregationsfunktionen (avg, max, ...) mit having und geschachtelte Queries (Unteranfragen).
Von der ANSI standardisiert, etwa SQL99 oder SQL3. Es gibt objektrelationale Erweiterungen.
SQL-Anfragen können direkt in die relationale Algebra überführt werden.
Besonderheiten sind: Mengen (union, intersect, minus), Gruppierung samt Aggregationsfunktionen (avg, max, ...) mit having und geschachtelte Queries (Unteranfragen).
Welche Arten von geschachtelten Anfragen gibt es?
Es gibt korrelierte und unkorrelierte Anfragen. Bei korrelierten Anfragen greift die Unteranfrage auf Attribute der umschließenden Anfrage zu. Sie können manchmal zu einem Join entschachtelt werden
Unkorrelierte Anfragen haben den Vorteil, das sie nur einmal insgesamt ausgeführt werden müssen, statt einmal pro Tupel.
Unkorrelierte Anfragen haben den Vorteil, das sie nur einmal insgesamt ausgeführt werden müssen, statt einmal pro Tupel.
Welche Arten von Sichten gibt es?
Sichten werden aus verschiedenen Gründen verwendet:
- Für den Datenschutz: Sicht erstellen, die nur die für die Benutzergruppe relevanten Attribute enthält
- Zur Vereinfachung von Anfragen: Oft verwendete, komplexe Anfragen als Sicht speichern. DRY-Prinzip (Don't repeat yourself)
- Zur Gewährleistung der Datenunabhängigkeit: Um Schema verändern zu können, etwa Spalten umzubennen, ohne die Applikationen zu verändern.


Wie kann ich in der DB Integrität erzwingen?
Es gibt statische und dynamische Integritätsbedingungen.
Statisch: Zu jedem Zeitpunkt muss der Datenbestand die Bedingung erfüllen, also eine Invariante:
Dynamisch als Trigger. Ein Trigger wird für die gewünschte Operation (UPDATE, ...) gestartet und prüft alten und neuen Wert durch eine Funktion. Kann den neuen Wert verändern.
Wenn nicht anders angegeben, weisen Integritätsbedingungen das Statement oder die Transaktion bei Fehler zurück.
Statisch: Zu jedem Zeitpunkt muss der Datenbestand die Bedingung erfüllen, also eine Invariante:
- Primärschlüssel, Fremdschlüssel (referentielle Integrität mit Zurückweisen, Kaskadieren oder Nullen)
- Einfache statische Bedingungen über check-Statement pro Attribut
- Komplexe statische Bedingungen über constraints-Statement pro Relation (können auch als Assertions benannt separat gespeichert werden)
Dynamisch als Trigger. Ein Trigger wird für die gewünschte Operation (UPDATE, ...) gestartet und prüft alten und neuen Wert durch eine Funktion. Kann den neuen Wert verändern.
Wenn nicht anders angegeben, weisen Integritätsbedingungen das Statement oder die Transaktion bei Fehler zurück.
Tags: Folienpaket 5
Quelle:
Quelle:
Wie ist das mit der Zugriffskontrolle?
Zugriffskontrolle dient sowohl der Privacy (User muss nicht mehr sehen als er auch verarbeiten muss) als auch der Security (User darf nicht schreibend auf Tupel zugreifen können, die er nicht verändern muss).
Erzielt durch Authentifizierung und Zugriffsrechte mit GRANT.
Erzielt durch Authentifizierung und Zugriffsrechte mit GRANT.
Tags: Folienpaket 5
Quelle:
Quelle:
Warum relationale Entwurfstheorie?
Das Ziel ist, "gute" relationale Schemata zu definieren und auch algorithmisch herzuleiten. Jede Relation soll genau einer Objektmenge entsprechen und frei von Redundanzen sein. Die drei Anomalien treten nicht auf.
Beispiel für schlechtes Relationenschema:
Update-Anomalie: Sokrates zieht um,.
Einfüge-Anomalie: Neuer Prof ohne Vorlesung.
Löschanomalie: Vorlesung von Schlick löschen.
Beispiel für schlechtes Relationenschema:
| PersNr | Name | Raum | VorlNr | Titel |
| 2125 | Sokrates | 226 | 5041 | Ethik |
| 2125 | Sokrates | 226 | 5049 | Mäeutik |
| 2132 | Schlick | 52 | 5259 | Der Wiener Kreis |
Update-Anomalie: Sokrates zieht um,.
Einfüge-Anomalie: Neuer Prof ohne Vorlesung.
Löschanomalie: Vorlesung von Schlick löschen.
Tags: Kapitel 6
Quelle:
Quelle:
Funktionale Abhängigkeit
Schema:  (R ist geschwungen!)
(R ist geschwungen!)
Ausprägung: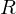
Seien , dann ist
, dann ist
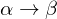 ("Alpha bestimmt Beta") genau denn wenn
("Alpha bestimmt Beta") genau denn wenn 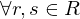 mit
mit 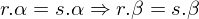
Notation: oder
oder 
(R ist geschwungen!)Ausprägung:
Seien
, dann ist ("Alpha bestimmt Beta") genau denn wenn mit Notation:
oder Schlüssel
 ist ein Super-Schlüssel, falls gilt:
ist ein Super-Schlüssel, falls gilt: 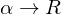 .
.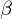 ist voll funktional abhängig (fva) von
ist voll funktional abhängig (fva) von 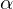 genau dann wenn gilt:
genau dann wenn gilt:-
- kann nicht mehr verkleinert werden, d.h.
 folgt, dass
folgt, dass  nicht gilt
nicht gilt
Notation für fva:

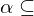 ist ein Kandidatenschlüssel, falls ein minimaler Schlüssel ist:
ist ein Kandidatenschlüssel, falls ein minimaler Schlüssel ist: 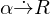
Attribut
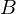 heisst Schlüsselattribut, wenn in einem der Kandidatenschlüssel vokommt.
heisst Schlüsselattribut, wenn in einem der Kandidatenschlüssel vokommt.Tags: Kapitel 6 Folie 8
Quelle:
Quelle:
Wie kann ich funktionale Abhängigkeiten herleiten?
Dazu dienen die Armstrong-Axiome:
Diese Axiome sind vollständig und korrekt. Weitere Axiome zur leichteren Herleitung:
- Reflexivität: Falls
 , dann gilt immer . Es gilt immer
, dann gilt immer . Es gilt immer 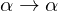
- Verstärkung: Falls gilt, dann gilt auch
 .
. - Transitivität: Falls und
 gilt, dann gilt auch
gilt, dann gilt auch  .
.
Diese Axiome sind vollständig und korrekt. Weitere Axiome zur leichteren Herleitung:
- Vereinigungsregel: Wenn und gelten, gilt auch
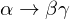
- Dekompositionsregel: Inverse der Vereinigungsregel
- Pseudotransitivitätsregel: Wenn und
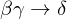 gelten, dann gilt auch
gelten, dann gilt auch  .
.
Tags:
Quelle: Kapitel 6 Folie 11
Quelle: Kapitel 6 Folie 11
Hintergrundspeicher
Hintergrundspeicher ist 2-3 Größenordnungen langsamer als RAM, wobei Random I/O nochmal 1-2 Größenordnungen langsamer als sequentieller Zugriff ist.
Zur Erhöhung der Fehlertoleranz werden of Disk Arrays verwendet:
Ideal: Verteilung der "Hitze", also der Lokalität der Zugriffe gleichmäßig über alle Platten und Bereiche.
Zur Erhöhung der Fehlertoleranz werden of Disk Arrays verwendet:
- RAID 0 = Striping: Mehr Read-Speed, schlechtere Toleranz
- RAID 1 = Mirroring: Doppelter Platzbedarf, schnelleres Lesen, doppelte Ausfallsicherheit, minimal langsameres Schreiben
- RAID 0+1 = Striping auf RAID 1: Schneller als RAID 1
- RAID 3 = Striping auf Bit-Ebene mit Paritätsplatte: Langsamer Zugriff, synchrones Lesen über alle Platten nötig
- RAID 4 = Striping auf Block-Ebene mit Paritätsplatte: Schneller, aber Paritätsplatte ist Flaschenhals
- RAID 5 = Striping auf Block-Ebene, Parität verteilt: Guter Ausgleich zwischen Platzbedarf und Geschwindigkeit
Ideal: Verteilung der "Hitze", also der Lokalität der Zugriffe gleichmäßig über alle Platten und Bereiche.
Tags:
Quelle: Kapitel 7
Quelle: Kapitel 7
Wie schneller Tupel auf Hintergrundspeicher finden?
Dazu dienen Indexstrukturen. Statt eines Table Scans muss nur der kleinere Index durchsucht werden, und selbst im Worst Case nicht alle Seiten davon. Dafür müssen sie gewartet werden. Also schnelleres Lesen, langsameres Schreiben.
Bäume sind gut für Daten, bei denen unkompliziert eine Ordnung aufgestellt werden kann, vor allem numerische Werte. ISAM-Strukturen entsprechen flachen Präfix-Bäumen, intuitiv dem Daumenindex eines Lexikons. Hashing ist optimal für alle nicht-numerischen Objekte, wichtig ist, dass sich das Hash schnell berechnen lässt.
Bäume sind gut für Daten, bei denen unkompliziert eine Ordnung aufgestellt werden kann, vor allem numerische Werte. ISAM-Strukturen entsprechen flachen Präfix-Bäumen, intuitiv dem Daumenindex eines Lexikons. Hashing ist optimal für alle nicht-numerischen Objekte, wichtig ist, dass sich das Hash schnell berechnen lässt.
Tags:
Quelle: Kapitel 7
Quelle: Kapitel 7
B-Bäume
Normale Binärbäume lassen sich schlecht auf Seiten abbilden und sind deswegen ungeeignet. Besser sind da B-Bäume, deren Knotengrößen auf Seitengröße abgestimmt werden und auf eine Seite abgebildet werden. Jeder Eintrag im Knoten umfasst Schlüssel und Tupel.
Die Anzahl der Seitenzugriffe beim Zugriff entspricht der Höhe des Baums, durch die Balancierung ist jedes Blatt gleich weit weg von der Wurzel. Jeder Knoten hat zwischen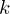 und
und  Einträge, nur die Wurzel hat
Einträge, nur die Wurzel hat  Einträge. Auf
Einträge. Auf 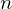 Einträge folgen an Nicht-Blättern
Einträge folgen an Nicht-Blättern  Kinder.
Kinder.
Beim Löschen oder Einfügen muss der Baum ggf. neu balanciert werden, damit diese Eigenschaften erfüllt werden.
Besser: B+-Bäume
Die Anzahl der Seitenzugriffe beim Zugriff entspricht der Höhe des Baums, durch die Balancierung ist jedes Blatt gleich weit weg von der Wurzel. Jeder Knoten hat zwischen
und Einträge, nur die Wurzel hat Einträge. Auf Einträge folgen an Nicht-Blättern Kinder.Beim Löschen oder Einfügen muss der Baum ggf. neu balanciert werden, damit diese Eigenschaften erfüllt werden.
Besser: B+-Bäume
Tags:
Quelle: Kapitel 7
Quelle: Kapitel 7
B+-Bäume
Bei flachen Bäumen müssen weniger Seiten nachgeladen werden. Für flache Bäume ist der B+-Baum gut, denn er hat die Tupel nur in den Blättern und deswegen mehr Elemente im Knoten -> flachere Bäume. Ausserdem verweist jedes Blatt auf Vorgänger und Nachfolger für guten sequentiellen Zugriff (Scans, Ranges). Und Referenzschlüssel müssen nicht realen Schlüsseln entsprechen, so können die Blätter besser ausgelastet werden.
Ansonsten gleiche Eigenschaften wie B-Baum.
Noch besser: Präfix-B+-Bäume:
Diese sind gerade bei der Indizierung von Zeichenketten sehr nützlich, da nur ein Teil des Schlüssels als Referenzschlüssel verwendet wird und es so zu einer besseren Verzweigung führt (und Schlüssel noch kleiner).
Ansonsten gleiche Eigenschaften wie B-Baum.
Noch besser: Präfix-B+-Bäume:
Diese sind gerade bei der Indizierung von Zeichenketten sehr nützlich, da nur ein Teil des Schlüssels als Referenzschlüssel verwendet wird und es so zu einer besseren Verzweigung führt (und Schlüssel noch kleiner).
Hashing
Bei Bäumen hat man immer noch log(n) Seitenzugriffe, einen pro Kantenverfolgung. Beim Hashing wird eine fast eindeutige Zuordnung von Schlüssel zu Bucket erreicht.
Statisches Hashing:
Erweiterbares Hashing:
Statisches Hashing:
- A priori Speicher alloziieren, nachträgliche Vergrößerung ist durch Rehashing teuer.
- Hashfunktion meist mod Anzahl Buckets.
Erweiterbares Hashing:
- Präfix des Hashwertes der Länge n zur Bestimmung des Buckets verwendet.
- Anfangs kleiner Präfix, kann wachsen.
- Zwischen globaler Tiefe (n) und lokaler Tiefe (Anzahl Bits, die in diesem Bucket wirklich verwendet werden) unterscheiden
- Bei Overflow globale Tiefe und ggf. lokale Tiefe erhöhen
- Bei Löschen falls lokale Tiefe überall < globale Tiefe, globale Tiefe senken
Tags:
Quelle: Kapitel 7
Quelle: Kapitel 7
Mehrdimensionale Indexstrukturen
Manchmal müssen mehrere Attribute in den Index aufgenommen werden, etwa in CAD, GIS, etc. Anfragen sind dann Punkt- oder Bereichsabfragen. Bei eindimensionalen Indizes muss eine aufwändige Schnittmengenbildung erfolgen.
Wertebereiche sind .
.
Mögliche Abfragen:
Eigenschaften: Atomare Gebiete (rechteckig), vollständig (alle Gebiete decken gesamten Datenraum ab), disjunkt
R-Baum: atomar, k-D-Baum: atomar, disjunkt, vollständig
Wertebereiche sind
.Mögliche Abfragen:
- Exact Match Query
- Partial Match Query, wo ein Teil der Dimensionen gegeben ist
- Range Query mit Suchintervall für alle Dimensionen
- Partial Range Query mit Suchintervall für manche Dimensionen
Eigenschaften: Atomare Gebiete (rechteckig), vollständig (alle Gebiete decken gesamten Datenraum ab), disjunkt
R-Baum: atomar, k-D-Baum: atomar, disjunkt, vollständig
Tags:
Quelle: Kapitel 7
Quelle: Kapitel 7
Was passiert denn, wenn ich eine SQL-Anfrage gestellt habe?
Die Anfrage stellt zwar das "was" dar, aber nicht, "wie" es gesucht werden soll. Jetzt wird die SQL-Abfrage über einen algebraischen Ausdruck in Code überführt, wobei dieser i. Alg. nicht optimal ist, es soll nur der worst-case vermieden werden. Es können mehrere "wie" zu einem was gefunden werden.
Der Ablauf ist:
Der Ablauf ist:
- Deklarative Anfrage -> Scanner, Parser, Sichtenauflösung -> Algebraischer Ausdruck ("kanonische Übersetzung")
- -> Anfrage-Optimierer (logische Optimierung) -> Auswertungs-Plan (QEP)
- -> Code-Erzeugung, Ausführung (physische Optimierung)
Tags:
Quelle: Kapitel 8
Quelle: Kapitel 8
Anfrageoptimierung
Es gibt folgende Äquivalenzerhaltende Transformationsregeln:
1. Aufbrechen von Konjunktionen im Selektionsprädikat:
2. ist kommutativ
ist kommutativ 
3.-Kaskaden: Falls  , dann gilt
, dann gilt

4. Vertauschen von und
Falls die Selektion sich nur auf die Attribute der Projektionsliste bezieht, können die beiden Operationen vertauscht werden:
der Projektionsliste bezieht, können die beiden Operationen vertauscht werden: 
5. und sind kommutativ:
und sind kommutativ:

....
1. Aufbrechen von Konjunktionen im Selektionsprädikat:
2.
ist kommutativ 3.
-Kaskaden: Falls , dann gilt4. Vertauschen von
und Falls die Selektion sich nur auf die Attribute
der Projektionsliste bezieht, können die beiden Operationen vertauscht werden: 5.
und sind kommutativ:....
Tags:
Quelle: Kapitel 8
Quelle: Kapitel 8
Heuristische Anwendung der Transformationsregeln
Zur Anfrageoptimierung wird wie folgt vorgegangen:
- Konjunktive Selektionsprädikate werden in Kaskaden von -Operationen zerlegt.
- Selektionsoperationen werden soweit "nach unten" propagiert wie möglich.
- Bei
 werden Blattknoten so vertauscht, dass derjenige, der das kleinste Zwischenergebnis liefert, zuerst ausgewertet wird.
werden Blattknoten so vertauscht, dass derjenige, der das kleinste Zwischenergebnis liefert, zuerst ausgewertet wird. - Eine -Operation gefolgt von einer -Operation wird wenn möglich in eine -Operation umgeformt.
- Projektionen werden so weit wie möglich nach unten propagiert.
- Operationen wenn möglich zusammenfassen (
 , etc.)
, etc.)
Was passiert bei der physischen Optimierung?
Für einen logischen Operator kann es mehrere mögliche physische Operatoren geben.
Durch Iteratoren können alle Datenquelle eine abstrakte Schnittstelle anbieten und können so beliebig miteinander kombiniert werden: open, next, close, size, cost. Iteratoren werden dann zu einem baumförmigen Auswertungsplan kombiniert. Das ganze geschieht Pull-basiert, also die Wurzel fordert Elemente an.
Im Idealfall kann Pipelining angewendet werden: Jede Quelle sendet das nächste Element, und diese können direkt verknüpft werden. Pipeline-Breaker sind Operationen wie Sort, unique, Mengendifferenz bei denen erst die gesamte Datenmenge vorliegen muss, damit der Iterator weiter arbeiten kann.
Es werden nun alle denkbaren Anfrageauswertungspläne (QEP) generiert und deren Kosten bewertet.
Durch Iteratoren können alle Datenquelle eine abstrakte Schnittstelle anbieten und können so beliebig miteinander kombiniert werden: open, next, close, size, cost. Iteratoren werden dann zu einem baumförmigen Auswertungsplan kombiniert. Das ganze geschieht Pull-basiert, also die Wurzel fordert Elemente an.
Im Idealfall kann Pipelining angewendet werden: Jede Quelle sendet das nächste Element, und diese können direkt verknüpft werden. Pipeline-Breaker sind Operationen wie Sort, unique, Mengendifferenz bei denen erst die gesamte Datenmenge vorliegen muss, damit der Iterator weiter arbeiten kann.
Es werden nun alle denkbaren Anfrageauswertungspläne (QEP) generiert und deren Kosten bewertet.
Tags:
Quelle: Kapitel 8
Quelle: Kapitel 8
Wie werden die verschiedenen QEPs bewertet?
Jeder QEP wird anhand verschiedener Informationsquellen bewertet, der billigste Plan wird ausgeführt:
In das Kostenmodell gehen rein: der algebraische Ausdruck, Indexinformationen, Ballungsinformationen (Statistiken, Histogramme), DB-Kardinalitäten, Attributverteilungen (Statistiken). Heraus kommen die Ausführungskosten.
Wichtig ist dabei die Selektivität, die Abschätzung eines Suchprädikats: qualifizierende Tupel / Gesamtanzahl Tupel
Bei Schlüsseln und Equijoin sind diese bekannt, ansonsten durch z.B. Stichproben abzuschätzen.
- Kostenmodell
- Statistiken (müssen angelegt werden)
- Histogramme
- Kalibrierung gemäß verwendetem Rechner
- Abhängig vom verfügbaren Speicher
- Aufwands-Kostenmodell: Durchsatz-maximierend, Nicht Antwortzeit-minimierend
In das Kostenmodell gehen rein: der algebraische Ausdruck, Indexinformationen, Ballungsinformationen (Statistiken, Histogramme), DB-Kardinalitäten, Attributverteilungen (Statistiken). Heraus kommen die Ausführungskosten.
Wichtig ist dabei die Selektivität, die Abschätzung eines Suchprädikats: qualifizierende Tupel / Gesamtanzahl Tupel
Bei Schlüsseln und Equijoin sind diese bekannt, ansonsten durch z.B. Stichproben abzuschätzen.
Tags:
Quelle: Kapitel 8
Quelle: Kapitel 8
Wozu und wie verteilte Datenbanken?
Verteilte Datenbanken dienen dem geographisch verteilten Zugriff auf Datenbanken (verteilte Datenbanken, Data Warehousing) oder der Integration verschiedener Datenbanken (Multi-DBMS mit Legacy DBs). Eine Client-Server-Architektur mit einem zentralen DBMS-Server ist nicht gemeint.
Die Daten werden fragmentiert und auf den verschiedenen Servern gespeichert. Dabei muss zwischen horizontaler (Tupelmenge aufteilen) und vertikaler (Attributmengen auf verschiedenen Systemen zusammenfassen, Primärschlüssel auf allen) Fragmentierung unterschieden werden.
Die Daten müssen rekonstruierbar, vollständig und disjunkt (ein Datum ist nicht mehreren Fragmenten zugeordnet, nicht für Primärschlüssel) sein.
Die Daten werden fragmentiert und auf den verschiedenen Servern gespeichert. Dabei muss zwischen horizontaler (Tupelmenge aufteilen) und vertikaler (Attributmengen auf verschiedenen Systemen zusammenfassen, Primärschlüssel auf allen) Fragmentierung unterschieden werden.
Die Daten müssen rekonstruierbar, vollständig und disjunkt (ein Datum ist nicht mehreren Fragmenten zugeordnet, nicht für Primärschlüssel) sein.
Tags:
Quelle: Kapitel 9
Quelle: Kapitel 9
Wie verwendet man verteile Datenbanken?
vDBMS bieten verschiedene Grade der Transparenz:
Bei Fragmentierungstransparenz kann eine zentrale Anfrageübersetzung und -optimierung erfolgen. Bei Joins von Relationen auf unterschiedlichen Hosts ohne Filter:
Oder mit Filter: Nur distinkte Join-Attribute transferieren, Join ausführen und dann Ergebnis-Tupel nachladen.
- Fragmentierungstransparenz: "Idealzustand", Benutzer benötigen kein Wissen über die Fragmentierung.
- Allokationstransparenz: Benutzer müssen Fragmentierung kennen, aber nicht den "Aufenthaltsort" eines Fragments.
- Lokale Schema-Transparenz: Der Benutzer muss auch noch den Rechner kennen, auf dem ein Fragment liegt (nur möglich wenn überall dasselbe DBMS)
Bei Fragmentierungstransparenz kann eine zentrale Anfrageübersetzung und -optimierung erfolgen. Bei Joins von Relationen auf unterschiedlichen Hosts ohne Filter:
- Nested Loop: Jedes Tupel einzeln anfordern
- Argumentrelationen transferieren: Eine oder beide Relationen transferieren, dann lokal joinen.
Oder mit Filter: Nur distinkte Join-Attribute transferieren, Join ausführen und dann Ergebnis-Tupel nachladen.
Tags:
Quelle: Kapitel 9
Quelle: Kapitel 9
Transaktionen
Transaktionen werden mit der BOT-Operation gestartet, durch commit deren Änderungen in die Datenbasis übernommen und bei Abort die Datenbasis auf den Zustand vor BOT zurückgesetzt. Sowohl commit als auch abort führen zum Abschluss der Transaktion.
Zusätzlich können Anwendungen mit "define savepoint" einen solchen definieren, auf die die noch aktive Transaktion per "backup transaction" zurückgesetzt werden kann.
Transaktionen erfüllen die ACID-Eigenschaften.
Zusätzlich können Anwendungen mit "define savepoint" einen solchen definieren, auf die die noch aktive Transaktion per "backup transaction" zurückgesetzt werden kann.
Transaktionen erfüllen die ACID-Eigenschaften.
Tags:
Quelle: Kapitel 10
Quelle: Kapitel 10
Welche Arten von Fehlern können in DBMS auftreten?
- Lokale Fehler einer noch nicht commiteten Transaktion. Muss zurückgesetzt werden (R1-Recovery)
- Fehler mit Hauptspeicherverlust: Abgeschlossene TAs müssen erhalten bleiben (R2-Recovery), nicht abgeschlossene zurückgesetzt werden (R3-Recovery).
- Fehler mit Hintergrundspeicherverlust: R4-Recovery
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 10 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 10 von Prof. Staab und Dr. Sizov
Wie ist das mit der Speicherhierarchie und den Fehlern?
DBMS verwenden eine zweistufige Speicherhierarchie: Seiten werden vom Hintergrundspeicher in den In-Memory Puffer eingelagert und dort bearbeitet. Während der Bearbeitung werden sie fixiert (fixierte Seiten können nicht ausgelagert werden). Nach der Bearbeitung werden sie als dirty markiert und dann bei Gelegenheit ausgelagert.
Es gibt verschiedene Strategien dabei, wobei Redo und Undo im Falle von Hauptspeicherverlust sind:
Ersetzung von Puffer-Seiten:
Einbringen von Änderungen abgeschlossener TAs:
Es gibt verschiedene Strategien dabei, wobei Redo und Undo im Falle von Hauptspeicherverlust sind:
Ersetzung von Puffer-Seiten:
- Not-Steal: Dirty-Seiten können nicht ersetzt werden.
- Steal: Nur fixierte Seiten können nicht ersetzt werden -> Undo nötig
Einbringen von Änderungen abgeschlossener TAs:
- Force: Änderungen werden zum TA-Ende auf den Hintergrundspeicher geschrieben (synchron)
- Not-Force: Geänderte Seiten können im Puffer verbleiben (aber Dirty) -> Redo nötig
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Was tun gegen Datenverlust bei Hauptspeicherverlust?
Üblicherweise schreiben DBMS ein Log, mit Einträgen der Form: [LSN, TransaktionsID, PageID, Redo, Undo, PrevLSN].
LSN ist die eindeutige ID des Eintrags, monoton aufsteigend. PageID ist die Kennung der Seite, auf der die Änderung vollzogen wurde. Redo und Undo geben an, wie die Änderung vollzogen bzw. rückgängig gemacht werden kann. PrevLSN ist ein Zeiger auf den vorhergehenden Log-Eintrag dieser TA.
Beim Update einer Seite wird die LSN dieses Updates in der Seite vermerkt, so kann herausgefunden werden, ob hier das Before- oder After-Image vorliegt. Write Ahead Logging sorgt dafür, dass zur TA gehörende Logs vor dem commit geschrieben werden, und vor dem Auslagern einer Seite alle dazu gehörigen Logs geschrieben werden.
Beim Recovery müssen mit Hilfe des Logs Winner-TAs (vor crash abgeschlossene TAs) komplett vollzogen werden, Loser-TAs rückgängig gemacht werden.
LSN ist die eindeutige ID des Eintrags, monoton aufsteigend. PageID ist die Kennung der Seite, auf der die Änderung vollzogen wurde. Redo und Undo geben an, wie die Änderung vollzogen bzw. rückgängig gemacht werden kann. PrevLSN ist ein Zeiger auf den vorhergehenden Log-Eintrag dieser TA.
Beim Update einer Seite wird die LSN dieses Updates in der Seite vermerkt, so kann herausgefunden werden, ob hier das Before- oder After-Image vorliegt. Write Ahead Logging sorgt dafür, dass zur TA gehörende Logs vor dem commit geschrieben werden, und vor dem Auslagern einer Seite alle dazu gehörigen Logs geschrieben werden.
Beim Recovery müssen mit Hilfe des Logs Winner-TAs (vor crash abgeschlossene TAs) komplett vollzogen werden, Loser-TAs rückgängig gemacht werden.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Wie funktioniert der Wiederanlauf nach Hauptspeicherverlust?
1. Analyse:
2. Redo-Phase:
3. Undo-Phase:
Auch das Recovery wird geloggt, damit auch Abstürze während des Recoveries die Idempotenz nicht stören. Dazu werden CLRs (Compensation Log Records) für jede Undo-Operation angelegt, die beim nächsten Redo ausgeführt, beim Undo übersprungen werden. Notation mit spitzen Klammern.
- Temporäre Log-Datei wird analysiert
- Winner- und Loser-Mengen werden ermittelt
2. Redo-Phase:
- alle protokollierten Änderungen werden in der Reihenfolge der Ausführung in die Datenbasis eingebracht.
3. Undo-Phase:
- Die Änderungsoperationen der Loser-TAs werden in umgekehrter Reihenfolge rückgängig gemacht.
Auch das Recovery wird geloggt, damit auch Abstürze während des Recoveries die Idempotenz nicht stören. Dazu werden CLRs (Compensation Log Records) für jede Undo-Operation angelegt, die beim nächsten Redo ausgeführt, beim Undo übersprungen werden. Notation mit spitzen Klammern.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 11 von Prof. Staab und Dr. Sizov
Worauf ist im Mehrbenutzerbetrieb zu achten?
Es können folgende Fehler auftreten:
Deswegen will man die serielle Ausführung von Operationen ("Isolation") vorgaukeln, ohne auf die Vorzüge der verzahnten Ausführung zu verzichten.
Dazu müssen durch Synchronisation die Historien mindestens serialisierbar gemacht werden.
- Lost update:
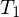 überschreibt Änderungen von
überschreibt Änderungen von  .
. - Dirty read: Lesen von temporären Werten, also vor commit.
- Phantomproblem: Dieselbe Operation führt zu zwei verschiedenen Ergebnissen.
Deswegen will man die serielle Ausführung von Operationen ("Isolation") vorgaukeln, ohne auf die Vorzüge der verzahnten Ausführung zu verzichten.
Dazu müssen durch Synchronisation die Historien mindestens serialisierbar gemacht werden.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Was ist Serialisierbarkeit?
Eine Historie ist eine zeitliche Anordnung der verzahnt ausgeführten Elementaroperationen von nebenläufig bearbeiteten Transaktion.
Eine Historie ist serialisierbar, wenn sie äquivalent zu einer seriellen Historie ist, aber parallel ausgeführt werden kann. Nur zwei Reads sind serialisierbar, alle anderen Konstellationen an Operationen sind Konfliktoperationen. Zwei Historien sind äquivalent, wenn sie die Konfliktoperationen der nicht abgebrochenen TAs in derselben Reihenfolge ausführen.
Historien haben einen Serialisierbarkeitsgraphen, bei dem Konfliktoperationen in unterschiedlichen TAs zu einer Kante von der TA führen, die die Operation zuerst ausgeführt hat, zur anderen TA. Ist dieser Graph azyklisch, ist die Historie serialisierbar.
Eine Historie ist serialisierbar, wenn sie äquivalent zu einer seriellen Historie ist, aber parallel ausgeführt werden kann. Nur zwei Reads sind serialisierbar, alle anderen Konstellationen an Operationen sind Konfliktoperationen. Zwei Historien sind äquivalent, wenn sie die Konfliktoperationen der nicht abgebrochenen TAs in derselben Reihenfolge ausführen.
Historien haben einen Serialisierbarkeitsgraphen, bei dem Konfliktoperationen in unterschiedlichen TAs zu einer Kante von der TA führen, die die Operation zuerst ausgeführt hat, zur anderen TA. Ist dieser Graph azyklisch, ist die Historie serialisierbar.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Andere Klassen von Historien
Eine Historie heisst rücksetzbar, falls immer die schreibende TA 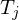 vor der lesenden Transkation
vor der lesenden Transkation  ihr commit durchführt, also
ihr commit durchführt, also  . Anders ausgedrückt: Eine TA darf erst ihr commit durchführen, wenn alle TAs, von denen sie gelesen hat, beendet sind. Rücksetzbare TAs können zurückgesetzt werden, ohne dass bereits abgeschlossene TAs in Mitleidenschaft gezogen werden.
. Anders ausgedrückt: Eine TA darf erst ihr commit durchführen, wenn alle TAs, von denen sie gelesen hat, beendet sind. Rücksetzbare TAs können zurückgesetzt werden, ohne dass bereits abgeschlossene TAs in Mitleidenschaft gezogen werden.
Historien ohne kaskadierendem Rücksetzen (ACA) zwingen bei ihrem Abbruch andere TAs, die von ihnen gelesen haben nie zum Abbruch, sind also eine Untermenge der rücksetzbaren Historien.
Strikte Historien überschreiben nie veränderte Daten einer noch laufenden Transaktion, sind also eine Untermenge der ACA-Historien.
vor der lesenden Transkation ihr commit durchführt, also . Anders ausgedrückt: Eine TA darf erst ihr commit durchführen, wenn alle TAs, von denen sie gelesen hat, beendet sind. Rücksetzbare TAs können zurückgesetzt werden, ohne dass bereits abgeschlossene TAs in Mitleidenschaft gezogen werden.Historien ohne kaskadierendem Rücksetzen (ACA) zwingen bei ihrem Abbruch andere TAs, die von ihnen gelesen haben nie zum Abbruch, sind also eine Untermenge der rücksetzbaren Historien.
Strikte Historien überschreiben nie veränderte Daten einer noch laufenden Transaktion, sind also eine Untermenge der ACA-Historien.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Wie wird Serialisierbarkeit technisch umgesetzt?
Der DBMS-Scheduler reiht die Operationen so, dass sie mindestens serialisierbar sind, meistens auch ohne Kaskadieren zurücksetzbar (also ##ACA \cap \SR).
Dazu gibt es verschiedene Ansätze:
Dazu gibt es verschiedene Ansätze:
- sperrbasierte Synchronisation (häufig verwendet)
- Zeitstempel-basierte Synchronisation
- und statt den obigen pessimistischen Verfahren die optimistische Synchronisation (vor allem für vorwiegend lesende Zugriffe a la LDAP)
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Wie funktioniert die sperrbasierte Synchronisation?
Es gibt zwei Sperrmodi, S (Shared) und X (eXclusive Lock), wobei ein X-Lock nur auf ein ungesperrtes Objekt gegeben werden kann, S-Lock aber auf ein bereits mit S-Lock versehenes Objekt. Kann eine Sperre nicht gegeben werden, muss die Transaktion auf die Freigabe warten (eigene Sperren müssen nicht erneut geholt werden).
Als Grundlage dient das Zwei-Phasen-Sperrprotokol (2PL). Zuerst kommt die Wachstumsphase, in der Sperren nur angefordert werden, und die Schrumpfphase, wo nur Sperren freigegeben werden. Am TA-Ende müssen alle Sperren freigegeben werden. 2PL erzwingt Serialisierbarkeit, aber Deadlocks sind möglich.
Als Erweiterung gibt es das strenge 2PL, bei dem alle Sperren bis TA-Ende gehalten werden (keine Schrumpfphase). Damit ist kaskadierendes Rücksetzen ausgeschlossen.
Als Grundlage dient das Zwei-Phasen-Sperrprotokol (2PL). Zuerst kommt die Wachstumsphase, in der Sperren nur angefordert werden, und die Schrumpfphase, wo nur Sperren freigegeben werden. Am TA-Ende müssen alle Sperren freigegeben werden. 2PL erzwingt Serialisierbarkeit, aber Deadlocks sind möglich.
Als Erweiterung gibt es das strenge 2PL, bei dem alle Sperren bis TA-Ende gehalten werden (keine Schrumpfphase). Damit ist kaskadierendes Rücksetzen ausgeschlossen.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Was ist mit den Deadlocks? Wie verhindere ich sie?
Deadlocks können entdeckt und aufgelöst werden:
Oder vermieden werden:
- Brute-Force: Nach einem Time-Out werden TAs zurückgesetzt. Schwierig, eine Balance zwischen zu kurz (unnötiges Zurücksetzen wegen Warten auf Ressourcen wie CPU) und zu lang (zu viele Deadlocks geduldet)
- Zyklenerkennung: Aufwändiger aber präziser. Wenn der Wartegraph Zyklen aufweist liegt Deadlock vor
Oder vermieden werden:
- Preclaiming mit strengem 2PL: Transaktionen werden erst begonnen, wenn alle Sperranforderungen erfüllt sind. Man weiss allerdings oft nicht, welche Sperren man braucht und müsste auf Verdacht anfordern -> zuviel Belegung
- Zeitstempel: Jede TA kriegt einen Timestamp. Nun will eine Sperre erwerbenm die von gehalten wird. Nun gibt es zwei Strategien. Bei Wound-Wait wird abgebrochen, wenn älter ist, sonst wartet auf Freigabe. Bei Wait-Die wartet , wenn älter ist, ansonsten wird abgebrochen.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Sperrgranularität
Bei Multi-Granularity Locking (MGL) gibt es nicht nur Sperren auf Satzebene, sondern auch auf Seiten, Segmente oder der Datenbasis.
Bei kleiner Sperrgranularität ist der Aufwand zur Verwaltung der Sperren sehr groß, bei großer Granularität wird zuviel unnötig gesperrt. Daher MGL.
Dabei werden neue Sperrmodi eingeführt (Intention Share=IS, Intention Exclusive=IX). Bevor S oder IS gewährt wird, muss man alle übergeordneten Hierarchieelemente mit IS oder IX gesperrt haben. Bevor X oder IX gewährt wird, muss man alle übergeordneten in IX haben. Freigabe bottom-up.
Bei kleiner Sperrgranularität ist der Aufwand zur Verwaltung der Sperren sehr groß, bei großer Granularität wird zuviel unnötig gesperrt. Daher MGL.
Dabei werden neue Sperrmodi eingeführt (Intention Share=IS, Intention Exclusive=IX). Bevor S oder IS gewährt wird, muss man alle übergeordneten Hierarchieelemente mit IS oder IX gesperrt haben. Bevor X oder IX gewährt wird, muss man alle übergeordneten in IX haben. Freigabe bottom-up.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Wie kann man Phantomprobleme beseitigen?
Selbst wenn beim Löschen und Einfügen automatisch X-Sperren vergeben werden ist das Phantomproblem nicht beseitigt. Deshalb muss der Zugriffsweg zusätzlich gesperrt werden, auf dem man zu dem Objekt gelangt ist.
Wenn also jemand mit Hilfe des Index liest, wird der gelesene Bereich im Index gesperrt. Will eine andere TA dort ein Tupel einfügen, muss sie warten.
Wenn also jemand mit Hilfe des Index liest, wird der gelesene Bereich im Index gesperrt. Will eine andere TA dort ein Tupel einfügen, muss sie warten.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Wie funktioniert Zeitstempel-basierte Synchronisation?
Jede TA bekommt zu Beginn einen Zeitstempel TS. Jedem Datum in der Datenbasis werden zwei Marken zugeordnet: readTS(A) und writeTS(A), jeweils der TS der jüngsten Transaktion, die A gelesen bzw. geschrieben hat.
Will nun A lesen (also  ):
):
Will A schreiben:
Will nun
A lesen (also ):- Falls
 muss zurückgesetzt werden.
muss zurückgesetzt werden. - Andernfalls kann die Operation ausgeführt werden.
Will
A schreiben:- Falls
 wurde A zwischenzeitlich von einer jüngeren TA gelesen, also muss zurückgesetzt werden.
wurde A zwischenzeitlich von einer jüngeren TA gelesen, also muss zurückgesetzt werden. - Falls gab es zwischenzeitlich einen Schreibzugriff einer jüngeren TA, also wieder zurücksetzen (sonst lost update).
- Andernfalls schreiben und
 setzen.
setzen.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Optimistische Synchronisation
Geht davon aus, dass Konflikte selten auftreten. TAs werden einfach ausgeführt und im Nachhinein geprüft, ob ein Konflikt aufgetreten ist.
1. Lesephase: Änderungsoperationen werden zunächst auf lokalen Kopien ausgeführt.
2. Validierungsphase: Prüft, ob TA zwischenzeitlich mit anderen TAs in Konflikt geraten ist. Jede TA kriegt in der Validierungsphase einen Zeitstempel. Alle älteren TAs müssen nun entweder abgeschlossen sein oder aber keine der von dieser TA gelesenen Elemente geschrieben haben, sonst ist diese TA in Konflikt. Immer nur eine TA in der Validierungsphase!
3. Schreibphase: Alle Änderungen werden in die Datenbasis eingebracht.
1. Lesephase: Änderungsoperationen werden zunächst auf lokalen Kopien ausgeführt.
2. Validierungsphase: Prüft, ob TA zwischenzeitlich mit anderen TAs in Konflikt geraten ist. Jede TA kriegt in der Validierungsphase einen Zeitstempel. Alle älteren TAs müssen nun entweder abgeschlossen sein oder aber keine der von dieser TA gelesenen Elemente geschrieben haben, sonst ist diese TA in Konflikt. Immer nur eine TA in der Validierungsphase!
3. Schreibphase: Alle Änderungen werden in die Datenbasis eingebracht.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 12 von Prof. Staab und Dr. Sizov
Wofür steht ACID?
- Atomicity: Transaktionen sind atomar, werden also komplett durchgeführt oder zurückgerollt. Bsp.: Umbuchung eines Kontos auf ein anderes. Abbruch zwischen Ab- und Zubuchung nicht erlaubt.
- Consistency: Ein konsistenter DB-Zustand muss in einen konsistenten DB-Zustand übergeben Bsp.: doppelte Buchführung: Saldo muss gleich Null sein.
- Isolation: Jede Transaktion hat die DB "für sich allein". Bsp.: Ein Primärindex darf nicht doppelt vergeben werden.
- Durability: Änderungen erfolgreicher Transaktionen dürfen nicht verloren gehen.
Tags:
Quelle: DB1 Vorlesung 2007 Kapitel 10 von Prof. Staab und Dr. Sizov
Quelle: DB1 Vorlesung 2007 Kapitel 10 von Prof. Staab und Dr. Sizov
Wie können da jetzt diese Iteratoren zusammen arbeiten?
Es gibt verschiedene Strategien, die unterschiedliche Vorraussetzungen haben:
- Brute force: eine verschachtelte Schleife über alle Elemente
- Merge-Sort Join: Relationen werden parallel von oben nach unten abgearbeitet. An jeder Position ist bekannt, dass keine kleineren Tupel folgen. Dann identische Werte mergen. Beide Relationen müssen nach dem Join-Attribut sortiert sein. Achtung: Sobald ein erster Join-Partner gefunden wird, muss dieser markiert werden. Existieren auf beiden Seiten gleichwertige Tupel, müssen diese auch mit diesem Tupel verknüpft werden.
- Hash Join: Join-Attribute mit Hash-Funktion auf dieselben Buckets abbilden, wo zu joinende Tupel liegen. Problem: Wenn die zu erstellende Hashtabelle nicht komplett in RAM passt, wird es langsam (eine Seite pro Zugriff laden). Daher werden beide Relation partitioniert, so dass nur kleine Partitionen miteinander verglichen werden müssen: Build- und Probe-Phase für jede Partition.
Tags:
Quelle: Kapitel 8
Quelle: Kapitel 8
Transitive Hülle und kanonische Überdeckung von FDs
Gegeben sei eine Menge F von FDs.
Die Menge aller aus F logisch ableitbaren FDs wird als transitive Hülle F+ bezeichnet. Die Armstrong-Regeln bilden einen korrekten und vollständigen Ableitungskalkül für die FDs in F+.
Die kanonische Überdeckung ist intuitiv die kleinste noch äquivalente Menge von FDs. Diese wird durch vier Schritte aus einer Menge F von FDs der Form hergeleitet:
Die Menge aller aus F logisch ableitbaren FDs wird als transitive Hülle F+ bezeichnet. Die Armstrong-Regeln bilden einen korrekten und vollständigen Ableitungskalkül für die FDs in F+.
Die kanonische Überdeckung ist intuitiv die kleinste noch äquivalente Menge von FDs. Diese wird durch vier Schritte aus einer Menge F von FDs der Form
hergeleitet:- Linksreduktion: Für alle
 überprüfen, ob
überprüfen, ob 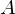 überflüssig ist (mit Hilfe der AttrHülle). Wenn ja, dann aus nehmen.
überflüssig ist (mit Hilfe der AttrHülle). Wenn ja, dann aus nehmen. - Rechtsreduktion: Für alle
 prüfen, ob überflüssig ist, ggf. aus nehmen.
prüfen, ob überflüssig ist, ggf. aus nehmen. - Alle leeren FDs der Form
 entfernen.
entfernen. - Mit Hilfe der Vereinigungsregel alle
 , ...
, ... 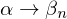 zusammenfassen
zusammenfassen
Tags:
Quelle: Kapitel 6, Folien 12-16
Quelle: Kapitel 6, Folien 12-16
Auf was muss man bei der Dekompisition von Relationen achten?
Es gibt zwei Korrektheitskriterien für die Zerlegung von Relationenschemata:
Das Biertrinker-Beispiel hat ein, in dem steht, wer was wo trinkt. Wenn man nun zwei neue Relationen macht (wer trinkt wo, und wer trinkt was), lässt sich daraus nur eine viel größere Relation rekonstruieren (wer trinkt was in allen Orten), die nicht mit der ursprünglichen übereinstimmt, also nicht verlustlos.
- Verlustlosigkeit: Die in der ursprünglichen Ausprägung enthaltenen Informationen müssen aus den neuen Ausprägungen rekonstruierbar sein. Gegenbeispiel: Biertrinker-Beispiel
- Abhängigkeitserhaltung: Die für geltenden funktionalen Abhängigkeiten müssen auf die neuen Schemata übertragbar sein. Also nicht FDs aufteilen.
Das Biertrinker-Beispiel hat ein
, in dem steht, wer was wo trinkt. Wenn man nun zwei neue Relationen macht (wer trinkt wo, und wer trinkt was), lässt sich daraus nur eine viel größere Relation rekonstruieren (wer trinkt was in allen Orten), die nicht mit der ursprünglichen übereinstimmt, also nicht verlustlos.Tags:
Quelle: Kapitel 6
Quelle: Kapitel 6
Normalformen?
Jede Normalform weist neben den Eigenschaften der "schwächeren" Normalformen eigene auf, sie schränkt die Menge der erlaubten Ausprägungen also ein.
- 1NF: Nur atomare Domänen, keine Relationen als Tupel etc
- 2NF: Intuitiv: In einer Relation dürfen nur Informationen über ein Konzept modelliert werden. Eine Relation
- to be continued...
mit zugehörigen FDs F ist in zweiter Normalform, falls jedes Nichtschlüssel-Attribut  voll funktional abhängig ist von jedem Kandidatenschlüssel der Relation. Eine Relation in 2NF ist frei von Anomalien.
voll funktional abhängig ist von jedem Kandidatenschlüssel der Relation. Eine Relation in 2NF ist frei von Anomalien.Tags:
Quelle: Kapitel 6
Quelle: Kapitel 6
Normalformen weiter
3NF: Intuitiv: Jeder Fakt darf nur einmal gespeichert werden.
Ein Relationenschema ist in dritter Normalform, wenn für jede für geltende FD mindestens eine dieser Bedingungen gilt:
Eine Relation lässt sich algorithmisch in Relationen in 3NF durch den Synthesealgorithmus zerlegen:
lässt sich algorithmisch in Relationen in 3NF durch den Synthesealgorithmus zerlegen:
Ein Relationenschema
ist in dritter Normalform, wenn für jede für geltende FD mindestens eine dieser Bedingungen gilt:-
 , d.h. die FD ist trivial
, d.h. die FD ist trivial - Das Attribut ist in einem Kandidatenschlüssel von enthalten
- ist Superschlüssel von
Eine Relation
lässt sich algorithmisch in Relationen in 3NF durch den Synthesealgorithmus zerlegen:- Kanonische Überdeckung
 bestimmen
bestimmen - Für jede FD
 ein neues Schema
ein neues Schema  generieren und FDs zuordnen.
generieren und FDs zuordnen. - Wenn keines dieser Schemata einen Kandidatenschlüssel enthält, muss ein Schema mit einem solchen generiert werden.
- Nun die Schemata eleminieren, die in einem anderen Schema enthalten sind.
Tags:
Quelle: Kapitel 6
Quelle: Kapitel 6
BCNF
Die Boyce-Codd-Normalform ist eine Verschärfung der 3NF. Eine Relation ist in 3NF, wenn für jede FD mindestens eine der beiden Abhängigkeiten gilt:
Man kann mit dem Dekompositionsalgorithmus eine Relation in 3NF in Relationenschemata  in BCNF überführen, dies ist nicht immer abhängigkeitserhaltend:
in BCNF überführen, dies ist nicht immer abhängigkeitserhaltend:
ist in 3NF, wenn für jede FD mindestens eine der beiden Abhängigkeiten gilt:- , d.h. die FD ist trivial
- ist Superschlüssel von .
Man kann mit dem Dekompositionsalgorithmus eine Relation
in 3NF in Relationenschemata in BCNF überführen, dies ist nicht immer abhängigkeitserhaltend:- Mit
 starten.
starten. - Solange noch ein
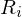 in
in  nicht in BCNF ist: * Eine nicht-triviale FD in
nicht in BCNF ist: * Eine nicht-triviale FD in
finden, die entweder kein Superschlüssel oder  ist. * in
ist. * in  und
und  zerlegen und statt in einfügen.
zerlegen und statt in einfügen.Tags:
Quelle: Kapitel 6
Quelle: Kapitel 6
Kartensatzinfo:
Autor: kread
Oberthema: Informatik
Thema: Datenbanken
Schule / Uni: Universität Koblenz-Landau
Ort: Koblenz
Veröffentlicht: 18.10.2010
