

Kann die Item Response Theory auch für Persönlichkeitsfragebögen eingesetzt werden?
JA
Itemschwierigkeit und Personenfähigkeit sind ganz klar assoziiert mit Leistungstests. Die IRT ist aber auch für die Analyse von Items zur Erfassung von Persönlichkeitsmerkmalen möglich (hier würde man die Personenfähigkeit als Ausprägung bezeichnen).
Obwohl in weiterer Folge aus Gründen der besseren Verständlichkeit angenommen wird, dass das zu messende Merkmal eine Fähigkeit ist und daher auch von der Personenfähigkeit und der „Lösungswahrscheinlichkeit“ eines Items gesprochen wird, ist die Item Response Theory (IRT) prinzipiell auch für die Analyse von Items zur Erfassung von Persönlichkeitsmerkmalen und Einstellungen geeignet.
Itemschwierigkeit und Personenfähigkeit sind ganz klar assoziiert mit Leistungstests. Die IRT ist aber auch für die Analyse von Items zur Erfassung von Persönlichkeitsmerkmalen möglich (hier würde man die Personenfähigkeit als Ausprägung bezeichnen).
Obwohl in weiterer Folge aus Gründen der besseren Verständlichkeit angenommen wird, dass das zu messende Merkmal eine Fähigkeit ist und daher auch von der Personenfähigkeit und der „Lösungswahrscheinlichkeit“ eines Items gesprochen wird, ist die Item Response Theory (IRT) prinzipiell auch für die Analyse von Items zur Erfassung von Persönlichkeitsmerkmalen und Einstellungen geeignet.
Tags: IRT, Persönlichkeitsfragebogen
Quelle: F230
Quelle: F230
Was ist die Grundidee bzw. sind die Grundannahmen der Item Response Theory?
Im Gegensatz zur klassischen Testtheorie, die erst beim Testwert ansetzt, sich jedoch nicht näher damit beschäftigt, wie es zu dem Testergebnis kommt, setzen Modelle der IRT bereits an der Formulierung des Zusammenhangs von latenter Dimension und manifester Variable an.
Ähnlich wie bei der Faktorenanalyse geht es also darum, dass manifeste Antwortverhalten durch die individuellen Merkmalsausprägungen der Personen erklären zu können.
Im Allgemeinen wird davon ausgegangen, dass drei Komponenten die beobachtete Antwort (bzw. die Wahrscheinlichkeit für eine beobachtete Antwort) beeinflussen. Bei den drei Komponenten handelt es sich um
Weiters wird bei den meisten Modellen im Rahmen der IRT von der Existenz einer einzigen latenten Dimension ausgegangen. Die beobachteten Antworten der Person (oder auch die vorliegenden Symptome) werden als Indikatoren dieser latenten Dimension aufgefasst. Mit ihrer Hilfe lässt sich die Ausprägung der Person auf der latenten Dimension abschätzen.
Der Zusammenhang zwischen der Ausprägung auf der latenten Dimension und der Wahrscheinlichkeit für eine bestimmte Antwort wird durch die Itemcharakteristik hergestellt. Es handelt sich dabei um eine eindeutige aber nicht zwingend eindeutig umkehrbare Funktion.
Eine „technische“ Annahme ist die „lokal stochastische Unabhängigkeit“ der Items. Das bedeutet, dass davon ausgegangen wird, dass in einer Gruppe von Personen mit gleicher Personenfähigkeit, die Lösungswahrscheinlichkeit eines Items unabhängig davon ist, ob die Person das zuvor vorgegebene Item gelöst hat oder nicht.
Für die praktische Anwendung bedeutet das, dass die Lösungen von Aufgaben nicht aufeinander aufbauen dürfen bzw. die Reihenfolge in der die Items bearbeitet werden, keine Rolle spielen darf.
Ähnlich wie bei der Faktorenanalyse geht es also darum, dass manifeste Antwortverhalten durch die individuellen Merkmalsausprägungen der Personen erklären zu können.
Im Allgemeinen wird davon ausgegangen, dass drei Komponenten die beobachtete Antwort (bzw. die Wahrscheinlichkeit für eine beobachtete Antwort) beeinflussen. Bei den drei Komponenten handelt es sich um
- Eigenschaften der Person (z.B. Fähigkeit),
- Eigenschaften des Items (z.B. Schwierigkeit) und
- zufällige Einflüsse.
Weiters wird bei den meisten Modellen im Rahmen der IRT von der Existenz einer einzigen latenten Dimension ausgegangen. Die beobachteten Antworten der Person (oder auch die vorliegenden Symptome) werden als Indikatoren dieser latenten Dimension aufgefasst. Mit ihrer Hilfe lässt sich die Ausprägung der Person auf der latenten Dimension abschätzen.
Der Zusammenhang zwischen der Ausprägung auf der latenten Dimension und der Wahrscheinlichkeit für eine bestimmte Antwort wird durch die Itemcharakteristik hergestellt. Es handelt sich dabei um eine eindeutige aber nicht zwingend eindeutig umkehrbare Funktion.
Eine „technische“ Annahme ist die „lokal stochastische Unabhängigkeit“ der Items. Das bedeutet, dass davon ausgegangen wird, dass in einer Gruppe von Personen mit gleicher Personenfähigkeit, die Lösungswahrscheinlichkeit eines Items unabhängig davon ist, ob die Person das zuvor vorgegebene Item gelöst hat oder nicht.
Für die praktische Anwendung bedeutet das, dass die Lösungen von Aufgaben nicht aufeinander aufbauen dürfen bzw. die Reihenfolge in der die Items bearbeitet werden, keine Rolle spielen darf.
Tags: IRT, Itemcharakteristik
Quelle: F231
Quelle: F231
Was ist die Itemcharakteristik? Welche Arten können unterschieden werden?
Die verschiedenen im Rahmen der IRT definierten Modelle unterscheiden sich im Wesentlichen hinsichtlich des angenommenen Zusammenhangs zwischen der Ausprägung auf der latenten Dimension und der Wahrscheinlichkeit für eine bestimmte Antwort.
Dieser Zusammenhang wird durch die Itemcharakteristik hergestellt. Es handelt sich dabei um eine eindeutige aber nicht zwingend eindeutig umkehrbare Funktion.
Das bedeutet, dass z.B. jeder Personenfähigkeit eine eindeutige Lösungswahrscheinlichkeit für ein bestimmtes Item zugeordnet ist, es aber Personen mit unterschiedlicher Fähigkeit geben kann, die dieselbe Lösungswahrscheinlichkeit bei einem Item besitzen.
Die grafische Darstellung dieses Zusammenhangs nennt sich Itemcharakteristik Kurve (ICC).
Es werden drei Typen von Itemcharakteristiken unterschieden
Dieser Zusammenhang wird durch die Itemcharakteristik hergestellt. Es handelt sich dabei um eine eindeutige aber nicht zwingend eindeutig umkehrbare Funktion.
Das bedeutet, dass z.B. jeder Personenfähigkeit eine eindeutige Lösungswahrscheinlichkeit für ein bestimmtes Item zugeordnet ist, es aber Personen mit unterschiedlicher Fähigkeit geben kann, die dieselbe Lösungswahrscheinlichkeit bei einem Item besitzen.
Die grafische Darstellung dieses Zusammenhangs nennt sich Itemcharakteristik Kurve (ICC).
Es werden drei Typen von Itemcharakteristiken unterschieden
- streng monotone Funktionen Bei streng monotonen Funktionen nimmt die Lösungswahrscheinlichkeit eines Items mit zunehmender Ausprägung der Person in der latenten Dimension stetig zu oder ab.
- monotone Funktionen Bei monotonen Funktionen können „Plateaus“ auftreten, sodass Personen mit ähnlichen Fähigkeiten gleiche Lösungswahrscheinlichkeiten haben.
- nicht monotone Funktionen Nicht monotone Funktionen können sowohl steigen als auch fallen.



Tags: IRT, Itemcharakteristik
Quelle: F234
Quelle: F234
Was ist die Guttman-Skala?
Itemcharakteristik nach Guttman.
Guttman (1950) war der erste, der einen Zusammenhang zwischen Personenfähigkeit und Lösungswahrscheinlichkeit modellierte. Es handelt sich dabei um die sogenannte „Guttman Skala“ auch „Skalogramm Analyse“ genannt.
Bei der Itemcharakteristik der „Guttman Skala“ handelt es sich um eine Sprungfunktion, wobei die Itemlösungswahrscheinlichkeit nur die Ausprägungen 0 und 1 annehmen kann. So mit ist das Modell nicht probabilistisch sondern deterministisch.
Trotzdem lassen sich damit wesentliche Erkenntnisse über die IRT ableiten.

- X-Achse: Personenfähigkeit / Y-Achse: Lösungswahrscheinlichkeit
- Alle Personen die eine Personenfähigkeit von < -2 haben, kann keiner die Aufgabe lösen. Ab einer Personenfähigkeit von >-2 können alle, immer die Aufgabe lösen.
Man kann die Itemschwierigkeit bzw. Lösungswahrscheinlichkeit ablesen an der Skala der Personenfähigkeit.
D.h. man gibt die Lösungswahrscheinlichkeit in der Skala der Personenfähigkeit an – d.h. es liegt den beiden Skalen der gleiche Maßstab zu Grunde.
Guttman (1950) war der erste, der einen Zusammenhang zwischen Personenfähigkeit und Lösungswahrscheinlichkeit modellierte. Es handelt sich dabei um die sogenannte „Guttman Skala“ auch „Skalogramm Analyse“ genannt.
Bei der Itemcharakteristik der „Guttman Skala“ handelt es sich um eine Sprungfunktion, wobei die Itemlösungswahrscheinlichkeit nur die Ausprägungen 0 und 1 annehmen kann. So mit ist das Modell nicht probabilistisch sondern deterministisch.
Trotzdem lassen sich damit wesentliche Erkenntnisse über die IRT ableiten.
- X-Achse: Personenfähigkeit / Y-Achse: Lösungswahrscheinlichkeit
- Alle Personen die eine Personenfähigkeit von < -2 haben, kann keiner die Aufgabe lösen. Ab einer Personenfähigkeit von >-2 können alle, immer die Aufgabe lösen.
Man kann die Itemschwierigkeit bzw. Lösungswahrscheinlichkeit ablesen an der Skala der Personenfähigkeit.
D.h. man gibt die Lösungswahrscheinlichkeit in der Skala der Personenfähigkeit an – d.h. es liegt den beiden Skalen der gleiche Maßstab zu Grunde.
Tags: Guttman-Skala, IRT
Quelle: F241
Quelle: F241
- Welches ist die einfachste Aufgabe?
- Welches ist die schwerste Aufgabe?
- Wie ist die Lösungswahrscheinlichkeit einer Person mit dem Personenfähigkeitsparameter von 2 für die 3 Aufgaben?

- Welches ist die schwerste Aufgabe?
- Wie ist die Lösungswahrscheinlichkeit einer Person mit dem Personenfähigkeitsparameter von 2 für die 3 Aufgaben?
- Welches ist die einfachste Aufgabe? Schwarz
- Welches ist die schwerste Aufgabe? Grün
- Wie ist die Lösungswahrscheinlichkeit einer Person mit dem Personenfähigkeitsparameter von 2?
Schwarz = 1; rot = 1; grün = 0
- Welches ist die schwerste Aufgabe? Grün
- Wie ist die Lösungswahrscheinlichkeit einer Person mit dem Personenfähigkeitsparameter von 2?
Schwarz = 1; rot = 1; grün = 0
Tags: Guttman-Skala, IRT
Quelle: F242
Quelle: F242
Was illustriert die Guttman-Skala?
Die Guttman Skala illustriert, dass
- die Schwierigkeit des Items und die Personenfähigkeit anhand der selben Skala abgelesen werden kann. Bei der Guttman Skala markiert die Personenfähigkeit, die an der Sprungstelle liegt, die Schwierigkeit des Items,
- zur Modellierung der Lösungswahrscheinlichkeit aller Items nur eine Dimension angenommen wird und
- anhand des Modells Vorhersagen gemacht werden können, die anhand der manifesten Items überprüfbar sind. Bei der Guttman Skala handelt es sich dabei um die „erlaubten“ Antwortmuster.
Tags: Guttman-Skala, IRT
Quelle: F243
Quelle: F243
Was ist das "Latent Distance Model" von Lazarsfeld?
Da die Guttman Skala unrealistische Forderungen an die Items stellt, wurde der deterministische Ansatz von Lazarsfeld durch einen probabilistischen ersetzt.
Bei der Itemcharakteristik des „Latent Distance Models“ handelt es sich ebenfalls um eine Sprungfunktion, wobei pro Items zwei Itemlösungswahrscheinlichkeiten modelliert
werden. Diese beiden Lösungswahrscheinlichkeiten können bei jedem Item anders sein und müssen aus den Daten geschätzt werden.
Die Lösungswahrscheinlichkeiten sind jedoch nicht 0 und 1 ... sondern 0,13 und 0,86. Hier ist also die Ratewahrscheinlichkeit mitberücksichtigt, trotzdem das richtige anzukreuzen, obwohl man die Personenfähigkeit nicht hat.

Dadurch sind alle Antwortmuster möglich, treten jedoch mit
unterschiedlichen Wahrscheinlichkeiten auf.
Dieses Modell ist ein extrem parameterreiches Modell, da man 3 unbekannte Parameter hat (untere Lösungswahrscheinlichkeit, Sprungstelle und obere Lösungswahrscheinlichkeit).
Obwohl das „Latent Distance“ - Modell realistischere Anforderungen an die Items stellt als die Guttman Skala, ist
die Annahme von konstant bleibenden Itemlösungswahrscheinlichkeiten bei steigender Personenfähigkeit wenig realistisch.
Realistischer erscheint, dass die Lösungswahrscheinlichkeit mit steigender Personenfähigkeit zunimmt.
Aus diesem Grund wurde nach anderen, realistischeren Funktionen gesucht .... z.B. dichotom logistische Modell von Rasch.
Bei der Itemcharakteristik des „Latent Distance Models“ handelt es sich ebenfalls um eine Sprungfunktion, wobei pro Items zwei Itemlösungswahrscheinlichkeiten modelliert
werden. Diese beiden Lösungswahrscheinlichkeiten können bei jedem Item anders sein und müssen aus den Daten geschätzt werden.
Die Lösungswahrscheinlichkeiten sind jedoch nicht 0 und 1 ... sondern 0,13 und 0,86. Hier ist also die Ratewahrscheinlichkeit mitberücksichtigt, trotzdem das richtige anzukreuzen, obwohl man die Personenfähigkeit nicht hat.
Dadurch sind alle Antwortmuster möglich, treten jedoch mit
unterschiedlichen Wahrscheinlichkeiten auf.
Dieses Modell ist ein extrem parameterreiches Modell, da man 3 unbekannte Parameter hat (untere Lösungswahrscheinlichkeit, Sprungstelle und obere Lösungswahrscheinlichkeit).
Obwohl das „Latent Distance“ - Modell realistischere Anforderungen an die Items stellt als die Guttman Skala, ist
die Annahme von konstant bleibenden Itemlösungswahrscheinlichkeiten bei steigender Personenfähigkeit wenig realistisch.
Realistischer erscheint, dass die Lösungswahrscheinlichkeit mit steigender Personenfähigkeit zunimmt.
Aus diesem Grund wurde nach anderen, realistischeren Funktionen gesucht .... z.B. dichotom logistische Modell von Rasch.
Tags: IRT, Latent Distance Model
Quelle: F244
Quelle: F244
Was ist die leichteste, was ist die schwerste Aufgabe?

Bei Sprungfunktionen bleibt die Itemschwierigkeit gleich (d.h. die Sprungstelle definiert die Itemschwierigkeit): das schwarze Item ist das leichteste, das grüne ist das schwerste.
Es ist dabei egal wie groß der Sprung ist.
Es ist dabei egal wie groß der Sprung ist.
Tags: IRT, Latent Distance Model
Quelle: F245
Quelle: F245
Was entwickelte Georg Rasch (Allgemein)?
- Georg Rasch, dänischer Mathematiker
- Fischer (Uni Wien) hat dieses Modell entdeckt und hat es in die Psychologie eingeführt – dies begründete die methodischen Schwerpunkte der Uni Wien. (Forscherkreis um Fischer: Gittler, Kubinger,…)
Georg Rasch hat als Itemcharakteristik die logistische Funktion gewählt.
(U = Unbekannte)

Keine Sprungfunktion, sondern ein kontinuierlicher Wachstum der Wahrscheinlichkeit.
Egal welche Zahl für U eingesetzt wird – das Ergebnis ist immer ein Wert zwischen 0 und 1.
+ ∞ = 1
- ∞ = 0
Mit höherer Personenfähigkeit wird die Lösungswahrscheinlichkeit kontinuierlich höher. = Streng monotone Funktion

U wird von Rasch definiert als Personenfähigkeit (xi) minus der Itemschwierigkeit (sigma/
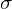 ). (Achtung ist hier keine Standardabweichung).
). (Achtung ist hier keine Standardabweichung).Tags: IRT, Rasch-Modell
Quelle: F247
Quelle: F247
Wann steigt die Lösungswahrscheinlichkeit (nach dem Rasch-Modell)
a) wenn die Itemschwierigkeit gleich bleibt?
b) wenn die Personenfähigkeit gleich bleibt?
a) wenn die Itemschwierigkeit gleich bleibt?
b) wenn die Personenfähigkeit gleich bleibt?
a) Wenn die Personenfähigkeit steigt (bei gleichbleibender Itemschwierigkeit).
b) Wenn die Itemschwierigkeit sinkt (bei gleichbleibender Personenfähigkeit).

b) Wenn die Itemschwierigkeit sinkt (bei gleichbleibender Personenfähigkeit).
Tags: IRT, Rasch-Modell
Quelle: F252
Quelle: F252
Erkläre diese Formel und was bedingt diese Formel

Der Parameter U soll nun mit den für das Modell wesentlichen
Kennwerten (der Personenfähigkeit und der Itemschwierigkeit) in
Verbindung gebracht werden.

Somit ist die Itemcharakteristik gegeben durch

Demnach haben Personen bei Items, deren Schwierigkeit der Personenfähigkeit entsprechen, eine Lösungswahrscheinlichkeit von p(+|v,i) = 0.5. Ist die Personenfähigkeit geringer als das Item schwierig ist p(+|v,i) < 0.5. Ist die Person fähiger als das Item schwierig, ist p(+|v,i) > 0.5.
Kennwerten (der Personenfähigkeit und der Itemschwierigkeit) in
Verbindung gebracht werden.
Somit ist die Itemcharakteristik gegeben durch
Demnach haben Personen bei Items, deren Schwierigkeit der Personenfähigkeit entsprechen, eine Lösungswahrscheinlichkeit von p(+|v,i) = 0.5. Ist die Personenfähigkeit geringer als das Item schwierig ist p(+|v,i) < 0.5. Ist die Person fähiger als das Item schwierig, ist p(+|v,i) > 0.5.
Tags: IRT, Rasch-Modell
Quelle: F249
Quelle: F249
WIe groß ist die Lösungswahrscheinlichkeit lt. Rasch-Modell wenn die Person gleich fähig wie die Aufgabe schwer ist?
Personen haben bei Items, deren Schwierigkeit der Personenfähigkeit entsprechen, eine Lösungswahrscheinlichkeit von p(+|v,i) = 0.5. Ist die Personenfähigkeit geringer als das Item schwierig ist p(+|v,i) < 0.5. Ist die Person fähiger als das Item schwierig, ist p(+|v,i) > 0.5.

1 / 1+1 = 0,5 (d.h. die Lösungswahrscheinlichkeit liegt bei 50%)

1 / 1+1 = 0,5 (d.h. die Lösungswahrscheinlichkeit liegt bei 50%)
Tags: IRT, Rasch-Modell
Quelle: F250
Quelle: F250
Was definiert die Schwierigkeit des Items (Itemschwierigkeit)
a) beim Modell von Guttman?
b) beim Rasch-Modell?
a) beim Modell von Guttman?
b) beim Rasch-Modell?
a) Die Sprungstelle markiert die Schwierigkeit des Items.
b) Wenn die Person gleich fähig ist wie das Item schwierig: die Lösungswahrscheinlichkeit liegt bei 50%.
In der Graphik (schwarze Linie) – Itemschwierigkeit 0 (= Personenfähigkeit 0) (da beide Werte mit dem gleichen Maß gemessen werden)

Was ist das leichteste Item? Grün.
b) Wenn die Person gleich fähig ist wie das Item schwierig: die Lösungswahrscheinlichkeit liegt bei 50%.
In der Graphik (schwarze Linie) – Itemschwierigkeit 0 (= Personenfähigkeit 0) (da beide Werte mit dem gleichen Maß gemessen werden)
Was ist das leichteste Item? Grün.
Tags: Guttman-Skala, IRT, Itemschwierigkeit, Rasch-Modell
Quelle: F251
Quelle: F251
Was ist ein dichotomes Item im Sinne des Rasch-Modells?
a) Was ist die Hauptstadt Italiens?
b) Fragestellungen bei der Millionenshow?
c) MC-Klausuren mit Teilpunkte?
d) MC-Klausuren ohne Teilpunkte?
a) Was ist die Hauptstadt Italiens?
b) Fragestellungen bei der Millionenshow?
c) MC-Klausuren mit Teilpunkte?
d) MC-Klausuren ohne Teilpunkte?
a) Hauptstadt Italiens?
JA – weil entweder ist die Antwort richtig oder falsch (man bewertet nicht ob etwas „richtiger“ ist, z.B. Florenz ist nicht richtiger als Paris).
b) Sind die Fragen in der Millionenshow dichotome Items?
JA – denn es hat nichts mit der Anzahl der Antwortalternativen zu tun – sondern nur damit ob die Antwort richtig oder falsch.
c) MC-Klausuren mit Teilpunkten?
NEIN, da Fragen auch als teilweise richtig anerkannt werden.
d)MC-Klausuren ohne Teilpunkte?
JA, weil die Antwort auf diese Frage nur richtig oder falsch sein kann.
Dichotomes Item != Zwei Antwortalternativen (= dichotomes Antwortformat)!!
Dadurch ist es der Fall, dass die Lösungswahrscheinlichkeit bei einem dichotomen Item nicht zwangsläufig 50% ist.
JA – weil entweder ist die Antwort richtig oder falsch (man bewertet nicht ob etwas „richtiger“ ist, z.B. Florenz ist nicht richtiger als Paris).
b) Sind die Fragen in der Millionenshow dichotome Items?
JA – denn es hat nichts mit der Anzahl der Antwortalternativen zu tun – sondern nur damit ob die Antwort richtig oder falsch.
c) MC-Klausuren mit Teilpunkten?
NEIN, da Fragen auch als teilweise richtig anerkannt werden.
d)MC-Klausuren ohne Teilpunkte?
JA, weil die Antwort auf diese Frage nur richtig oder falsch sein kann.
Dichotomes Item != Zwei Antwortalternativen (= dichotomes Antwortformat)!!
Dadurch ist es der Fall, dass die Lösungswahrscheinlichkeit bei einem dichotomen Item nicht zwangsläufig 50% ist.
Tags: IRT, Rasch-Modell
Quelle: Mitschrift VO09
Quelle: Mitschrift VO09
Wie sieht die Formel aus für die Wahrscheinlichkeit, dass eine Person v ein Item i nicht löst?
Die Wahrscheinlichkeit, dass eine Person v das Item i nicht
löst ist gegeben durch

Die Kurve der Wahrscheinlichkeit ein Item zu Lösen und ein Item nicht zu lösen, verlaufen gegenläufig.

löst ist gegeben durch
Die Kurve der Wahrscheinlichkeit ein Item zu Lösen und ein Item nicht zu lösen, verlaufen gegenläufig.
Tags: IRT, Rasch-Modell
Quelle: F253
Quelle: F253
Was bedeutet dieser Formel:

Dies eine weitere Art der Modelldarstellung des dichotom logistischen Modells von Rasch:

Tags: IRT, Rasch-Modell
Quelle: F256
Quelle: F256
Welche Forderungen hatte Rasch an sein Modell?
Diese vier Forderungen umfassen also die Forderung nach
Achtung: Spezifische Objektivität von Vergleichen != Testgütekriterium Objektivität
Diese Eigenschaften können mathematisch bewiesen werden.

- spezifischer Objektivität von Vergleichen (Punkt 1, 2) und
- erschöpfenden (suffizienten) Statistiken (Punkt 3, 4).
Achtung: Spezifische Objektivität von Vergleichen != Testgütekriterium Objektivität
- Das Verhältnis der Schwierigkeiten zweier Items soll unabhängig von der gewählten Stichprobe sein. Wenn 2 Items die gleiche Eigenschaft messen, dann muss der Unterschied der Schwierigkeit im Verhältnis bei den Populationen gleich sein
- Das Verhältnis der Fähigkeiten zweier Personen soll unabhängig davon sein, welche Aufgaben den Personen zur Ermittlung der Personenfähigkeiten vorgegeben wurden. Wenn Items die gleiche Eigenschaft erfassen, dann muss unabhängig davon welche Items welcher Population vorgegeben werden, muss das Verhältnis der Fähigkeit gleich bleiben.(Anlehnung: 10 Kilo sind schwerer als 5 Kilo, unabhängig davon wer das Gewicht hebt.)
- Die Anzahl der gelösten Aufgaben soll die gesamte Information der Daten über die Fähigkeit der Person beinhalten. Wenn Personen den gleichen Test erhalten und gleich viele Punkte erhalten, dann kann man sagen „Die Personen sind gleich fähig.“
- Die Anzahl an Personen, die ein Item lösen können, soll die gesamte Information der Daten über die Schwierigkeit des Items beinhalten. Es darf für die Itemschwierigkeit nicht von Bedeutung sein, welche Person welches Item gelöst hat. Es ist nur noch relevant wie viele Items eine Person löst und wie viele Items insgesamt gelöst wurden.
Diese Eigenschaften können mathematisch bewiesen werden.
Tags: IRT, Rasch-Modell
Quelle: F257
Quelle: F257
Wie sollen die Itemcharakteristik-Kurven beim Rasch-Modell aussehen (folgend der Forderung nach spezifischer Objektivität)?
Aus der Forderung nach spezifischer Objektivität folgt, dass sich die IC Kurven nicht schneiden dürfen. Die IC Kurven müssen im Modell von Rasch also dieselbe Steigung (=Diskrimination) haben.

Dadurch, dass sie sich nie schneiden dürfen, müssen die Itemcharakteristikkurven parallel sein.
Dadurch, dass sie sich nie schneiden dürfen, müssen die Itemcharakteristikkurven parallel sein.
Tags: IRT, Itemcharakteristik, Rasch-Modell
Quelle: F260
Quelle: F260
Was versteht man unter Diskriminationfähigkeit einer Itemcharakteristik-Kurve?
Diskriminationsfähigkeit: Ist die Eigenschaft, wie schnell die Itemcharakteristikkurve ansteigt.

Rasch fordert also Items mit der gleichen Diskriminationsfähigkeit.
- Je flacher der Anstieg eines Items ist, desto geringer ist die Diskriminationsfähigkeit
- Gutmans-Sprungfunktion hat eine 100%ige Diskriminationsfähigkeit.
Rasch fordert also Items mit der gleichen Diskriminationsfähigkeit.
Tags: Diskriminationsfähigkeit, IRT, Itemcharakteristik, Rasch-Modell
Quelle: F260
Quelle: F260
Wie kann die Existenz der erschöpfenden Statistik für das Rasch-Modell gezeigt/bewiesen werden?
Die Existenz der erschöpfenden Statistiken kann anhand der Likelihood der Daten gezeigt werden.
Die Likelihood der Daten ist die Wahrscheinlichkeit, EXAKT die erhobenen Daten zu erhalten.
Likelihood ist nur noch von den Randsummen (Anzahl der gelösten Items einer Person und Anzahl wie oft ein Item gelöst wurdE) abhängig und nicht von den konkreten Antworten einer Person.
Die Likelihood der Daten ist die Wahrscheinlichkeit, EXAKT die erhobenen Daten zu erhalten.
Likelihood ist nur noch von den Randsummen (Anzahl der gelösten Items einer Person und Anzahl wie oft ein Item gelöst wurdE) abhängig und nicht von den konkreten Antworten einer Person.
Tags: Existenz der erschöpfenden Statistik, IRT, Likelihood, Rasch-Modell
Quelle: F261
Quelle: F261
Wie ist die Vorgehensweise beim Likelihood um die Existenz der erschöpfenden Statistik zu zeigen?
Die Existenz der erschöpfenden Statistiken kann anhand der Likelihood der Daten gezeigt werden. Die Likelihood der Daten ist die Wahrscheinlichkeit, EXAKT die erhobenen Daten zu erhalten.
Wie sehen diese Daten im Modell von Rasch aus?

Tabelle: Person 1 hat Item 1 falsch beantwortet (0) und Item 2 richtig beantwortet (1), etc.
Gehen wir nun davon aus, wir können die Antwort, die eine
Person v auf ein Item i gegeben hat, in eine
Wahrscheinlichkeit umwandeln, mit der Person v die
gegebene Antwort auf Item i gibt. Dadurch erhalten wir:

Jetzt muss für jede Person und Item berechnet werden wie wahrscheinlich es ist, dass diese Person genau dieses Item löst/nicht löst = Antwortmuster einer Person
Geht man weiters davon aus, dass die Wahrscheinlichkeit der
Lösung von Item i durch Person v unabhängig davon ist,
welche und wie viele Items Person v zuvor gelöst hat (=lokal
stochastische Unabhängigkeit), so kann die
Wahrscheinlichkeit, dass Person v ihr Antwortmuster zeigt,
berechnet werde durch:

(nicht stochastische Unabhängigkeit wenn aufeinander aufbauende Aufgaben oder eine Person lernt zwischen den Aufgaben (z.B. durch Rückmeldung über Ergebnis))
Geht man nun noch davon aus, dass die von den Personen
erzielten Antwortmuster unabhängig sind, so ist die
Wahrscheinlichkeit die gegebenen Daten zu erhalten
(=Likelihood der Daten) gegeben durch:

Sind die Daten voneinander unabhängig? Ja, wenn sie nicht voneinander abschauen (ev. auch problematisch bei mündl. Prüfungen, Partnerarbeiten, Online-Testungen, Person füllt Test mehrfach aus)
Je nach Variante muss die entsprechende Variante gewählt werden – entweder der 1. Term oder der 2. Term. Dies wird automatisch erreicht durch avj bzw. 1-avj …. Da bei richtigen Antworten mit 1 kodiert werden erhält man beim 1. Term bei einer richtigen Antwort den Term hoch 1 und dem 2. Term mit hoch 0 und so wird bei einer richtigen Antwort z.B. nur der 1. Term verwendet.
In der Formel kommt v und i nicht weiter vor – d.h. für die Berechnung der Wahrscheinlichkeit genau diese konkrete Daten zu erhalten (Likelihood) muss nicht die konkrete Antwort der Person gewusst werden = Beweis für die Existenz der erschöpfenden Statistik.

Wie sehen diese Daten im Modell von Rasch aus?
Tabelle: Person 1 hat Item 1 falsch beantwortet (0) und Item 2 richtig beantwortet (1), etc.
Gehen wir nun davon aus, wir können die Antwort, die eine
Person v auf ein Item i gegeben hat, in eine
Wahrscheinlichkeit umwandeln, mit der Person v die
gegebene Antwort auf Item i gibt. Dadurch erhalten wir:
Jetzt muss für jede Person und Item berechnet werden wie wahrscheinlich es ist, dass diese Person genau dieses Item löst/nicht löst = Antwortmuster einer Person
Geht man weiters davon aus, dass die Wahrscheinlichkeit der
Lösung von Item i durch Person v unabhängig davon ist,
welche und wie viele Items Person v zuvor gelöst hat (=lokal
stochastische Unabhängigkeit), so kann die
Wahrscheinlichkeit, dass Person v ihr Antwortmuster zeigt,
berechnet werde durch:
(nicht stochastische Unabhängigkeit wenn aufeinander aufbauende Aufgaben oder eine Person lernt zwischen den Aufgaben (z.B. durch Rückmeldung über Ergebnis))
Geht man nun noch davon aus, dass die von den Personen
erzielten Antwortmuster unabhängig sind, so ist die
Wahrscheinlichkeit die gegebenen Daten zu erhalten
(=Likelihood der Daten) gegeben durch:
Sind die Daten voneinander unabhängig? Ja, wenn sie nicht voneinander abschauen (ev. auch problematisch bei mündl. Prüfungen, Partnerarbeiten, Online-Testungen, Person füllt Test mehrfach aus)
Je nach Variante muss die entsprechende Variante gewählt werden – entweder der 1. Term oder der 2. Term. Dies wird automatisch erreicht durch avj bzw. 1-avj …. Da bei richtigen Antworten mit 1 kodiert werden erhält man beim 1. Term bei einer richtigen Antwort den Term hoch 1 und dem 2. Term mit hoch 0 und so wird bei einer richtigen Antwort z.B. nur der 1. Term verwendet.
In der Formel kommt v und i nicht weiter vor – d.h. für die Berechnung der Wahrscheinlichkeit genau diese konkrete Daten zu erhalten (Likelihood) muss nicht die konkrete Antwort der Person gewusst werden = Beweis für die Existenz der erschöpfenden Statistik.
Tags: Existenz der erschöpfenden Statistik, IRT, Likelihood, Rasch-Modell
Quelle: F261
Quelle: F261
Wie ergibt sich die Likelihood-Formel hinsichtlich der Berechnung der Lösungswahrscheinlichkeit für richtige und falsche Antworten?
(Anm: muss vermutlich nicht so im Detail gewusst werden)
Im dichotom logistischen Modell von Rasch können Personen zwei unterschiedliche Antworten geben.
Entweder sie antworten korrekt (1) oder nicht (0). Die Wahrscheinlichkeiten hierfür sind:

Je nach gegebener Antwort, muss die entsprechende Variante gewählt werden. Dies wird erreicht durch

Je nach Variante muss die entsprechende Variante gewählt werden – entweder der 1. Term oder der 2. Term. Dies wird automatisch erreicht durch avj bzw. 1-avj …. Da bei richtigen Antworten mit 1 kodiert werden erhält man beim 1. Term bei einer richtigen Antwort den Term hoch 1 und dem 2. Term mit hoch 0 und so wird bei einer richtigen Antwort z.B. nur der 1. Term verwendet.


Demnach wird allen Personen, die einem Test mit den selben Items dieselbe Anzahl gelöster Aufgaben erzielen, derselbe Fähigkeitsparameter zugeordnet.
Die Erkenntnis, dass die erschöpfenden Statistiken nur gelten, wenn die Items den Anforderungen des Modells von Rasch (RM) entsprechen, hat weitreichende Konsequenzen.
U.a. bedeutet es, dass die im Rahmen der klassischen Testtheorie vorgenommene Summenbildung zur Gewinnung eines Rohscores nur fair ist, wenn die Items dem RM entsprechen.
Im dichotom logistischen Modell von Rasch können Personen zwei unterschiedliche Antworten geben.
Entweder sie antworten korrekt (1) oder nicht (0). Die Wahrscheinlichkeiten hierfür sind:
Je nach gegebener Antwort, muss die entsprechende Variante gewählt werden. Dies wird erreicht durch
Je nach Variante muss die entsprechende Variante gewählt werden – entweder der 1. Term oder der 2. Term. Dies wird automatisch erreicht durch avj bzw. 1-avj …. Da bei richtigen Antworten mit 1 kodiert werden erhält man beim 1. Term bei einer richtigen Antwort den Term hoch 1 und dem 2. Term mit hoch 0 und so wird bei einer richtigen Antwort z.B. nur der 1. Term verwendet.
- Rohscore von Person v: Wieviele Items hat die Person gelöst?
- Absolute Lösungshäufigkeit von Item i: Wie oft wurde dieses Item gelöst?
- In der Formel kommt v und i nicht weiter vor – d.h. für die Berechnung der Wahrscheinlichkeit genau diese konkrete Antwort zu erhalten (Likelihood) muss nicht die konkrete Antwort der Person gewusst werden = Beweis für die Existenz der erschöpfenden Statistik.
Demnach wird allen Personen, die einem Test mit den selben Items dieselbe Anzahl gelöster Aufgaben erzielen, derselbe Fähigkeitsparameter zugeordnet.
Die Erkenntnis, dass die erschöpfenden Statistiken nur gelten, wenn die Items den Anforderungen des Modells von Rasch (RM) entsprechen, hat weitreichende Konsequenzen.
U.a. bedeutet es, dass die im Rahmen der klassischen Testtheorie vorgenommene Summenbildung zur Gewinnung eines Rohscores nur fair ist, wenn die Items dem RM entsprechen.
Tags: Existenz der erschöpfenden Statistik, IRT, Likelihood, Rasch-Modell
Quelle: F265
Quelle: F265
Was ermöglicht die IRT dadurch, dass die Itemschwierigkeit unabhängig ist von der Personenfähigkeit?
Entspricht eine Menge von Items einem IRT Modell, so ermöglicht das Personen miteinander zu vergleichen, auch wenn sie nicht dieselben Aufgaben bearbeitet haben. Damit können die Tests an die Personen angepasst werden (=adaptives Testen).
Die beiden Arten des adaptiven Testens sind
Die beiden Arten des adaptiven Testens sind
- Tailored Testing (maßgeschneidertes Testen) und
- Branched Testing (verzweigtes Tests).
Tags: adaptiver Test, IRT
Quelle: F273
Quelle: F273
Wie können die Personen beim adaptiven Testen miteinander verglichen werden? Was sind die Vorteile des adaptiven Testens?
Die Vergleichbarkeit der Personen ist für den Fall, dass sie unterschiedliche Items bearbeiten jedoch nicht mehr über die Anzahl der gelösten Aufgaben, sondern nur noch über die geschätzte Personenparameter möglich.
Eine auf die Fähigkeiten der getesteten Personen abgestimmte Itemauswahl,
Bei der IRT darf man nicht mehr sagen: Personen die gleich viele Aufgaben gelöst haben sind gleich gut. Denn dies darf man nur sagen, wenn alle Personen die gleichen Items vorgelegt wurden.
Die Genauigkeit mit der wir eine Person messen können (Messfehler) hängt von der Vorgabe des Tests ab. Bei der klassischen Testtheorie geht man davon aus dass der Messfehler gleich groß ist. Bei der modernen Testtheorie kann man durch adaptives Testen den Messfehler reduzieren.
Eine auf die Fähigkeiten der getesteten Personen abgestimmte Itemauswahl,
- reduziert in vielen Fällen nicht nur die benötigte Testzeit und
- ermöglicht die Personen weitestgehend weder durch die Vorgabe von zu leichten Aufgaben zu „langweilen“ oder von zu schweren Aufgaben zu „demotivieren“, sondern
- erhöht auch die Genauigkeit der Schätzung des Personenparameters (Messfehler wird reduziert).
Bei der IRT darf man nicht mehr sagen: Personen die gleich viele Aufgaben gelöst haben sind gleich gut. Denn dies darf man nur sagen, wenn alle Personen die gleichen Items vorgelegt wurden.
Die Genauigkeit mit der wir eine Person messen können (Messfehler) hängt von der Vorgabe des Tests ab. Bei der klassischen Testtheorie geht man davon aus dass der Messfehler gleich groß ist. Bei der modernen Testtheorie kann man durch adaptives Testen den Messfehler reduzieren.
Tags: adaptives Testen, IRT
Quelle: F276
Quelle: F276
Wie kann die Parameterschätzung im Rasch-Modell erfolgen?
Die Schätzung der unbekannten Parameter erfolgt im Rasch Modell üblicherweise mit Hilfe der Maximum-Likelihood-Methode.
Hierbei werden die unbekannten Parameter so geschätzt, dass die Likelihood der Daten maximal wird.
Die Parameterschätzung benötigt man für die Schätzung der Personenfähigkeit bzw. der Itemschwierigkeit.


Hierbei werden die unbekannten Parameter so geschätzt, dass die Likelihood der Daten maximal wird.
Die Parameterschätzung benötigt man für die Schätzung der Personenfähigkeit bzw. der Itemschwierigkeit.
Tags: IRT, Maximum-Likelihood-Methode, Parameterschätzung, Rasch-Modell
Quelle: F277
Quelle: F277
Welche Methoden zur Modellkontrolle gibt es?
Um zu überprüfen, ob die vorliegenden Items dem dichotom logistischen Modell von Rasch entsprechen, können verschiedene Modelltests herangezogen werden.
Dazu gehören z.B.
Bei den Modellkontrollen wird überprüft ob/welche Item nicht das Rasch-Modell erfüllen.
Es werden solange Items aus dem Test entfernt bis die Modelltests nicht mehr signifikant sind.
Müssen mehr als in etwa 20% der Items entfernt werden, sollten die verbleibenden Items an einer neuen Stichprobe abermals geprüft werden.
Dazu gehören z.B.
- die grafische Modellkontrolle,
- der z-Test nach Wald,
- der bedingte Likelihood Quotienten Test nach Andersen und
- der Martin Löf Test.
Bei den Modellkontrollen wird überprüft ob/welche Item nicht das Rasch-Modell erfüllen.
Es werden solange Items aus dem Test entfernt bis die Modelltests nicht mehr signifikant sind.
Müssen mehr als in etwa 20% der Items entfernt werden, sollten die verbleibenden Items an einer neuen Stichprobe abermals geprüft werden.
Tags: IRT, Modellkontrollen, Rasch-Modell
Quelle: F290
Quelle: F290
Welche weiteren Modelle neben der IRT gibt es (Beispiele)?
Ausgehende von den Ideen von Georg Rasch wurden zahlreiche weitere Modelle entwickelt. Im Folgenden werden
kurz vorgestellt.
- die Modelle von Birnbaum (1968),
- das linear logistische Testmodell (LLTM) und
- die Erweiterung auf rangskalierte Daten
kurz vorgestellt.
Tags: IRT
Quelle: F312
Quelle: F312
Was sind die Birnbaum Modelle? Beschreibe diese.
Birnbaum (1968) stellte zwei Erweiterungen des dichotom logistischen Modells von Rasch vor, indem er unterschiedliche Diskriminations- und Rateparameter pro Item erlaubt.
Bei diesen Modellen handelt es sich um
Bei beiden Modellen ergeben sich wegen der relativ großen Zahl an Modellparametern häufig Probleme bei der Parameterschätzung.
Das zwei Parameter logistische Modell
Bei diesem Modell gibt es pro Item zwei Parameter, nämlich
Die Lösungswahrscheinlichkeit eines Items i durch Person v ist gegeben durch

Aufgrund der unterschiedlichen Diskriminationsparameter gibt es in diesem Modell schneidende IC Kurven, sodass die spezifische Objektivität bei diesem Modell nicht gegeben ist.

Das drei Parameter logistische Modell
Bei diesem Modell gibt es pro Item drei Parameter, nämlich
Die Lösungswahrscheinlichkeit eines Items i durch Person v ist gegeben durch

Auch hier schneiden die IC Kurven einander

Bei diesen Modellen handelt es sich um
- das zwei Parameter logistische Modell und
- das drei Parameter logistische Modell.
Bei beiden Modellen ergeben sich wegen der relativ großen Zahl an Modellparametern häufig Probleme bei der Parameterschätzung.
Das zwei Parameter logistische Modell
Bei diesem Modell gibt es pro Item zwei Parameter, nämlich
- den Itemschwierigkeitsparamter und
- den Diskriminationsparameter.
Die Lösungswahrscheinlichkeit eines Items i durch Person v ist gegeben durch
Aufgrund der unterschiedlichen Diskriminationsparameter gibt es in diesem Modell schneidende IC Kurven, sodass die spezifische Objektivität bei diesem Modell nicht gegeben ist.
Das drei Parameter logistische Modell
Bei diesem Modell gibt es pro Item drei Parameter, nämlich
- den Itemschwierigkeitsparamter,
- den Diskriminationsparameter und
- die Ratewahrscheinlichkeit.
Die Lösungswahrscheinlichkeit eines Items i durch Person v ist gegeben durch
Auch hier schneiden die IC Kurven einander
Tags: Birnbaum Modelle, IRT
Quelle: F313
Quelle: F313
Was ist das linear logistische Testmodell (LLTM)?
Das LLTM geht auf Scheiblechner (1972) und Fischer (1972, 1973) zurück und stellt ein restriktiveres Modell als das dichotom logistische Modell von Rasch dar.
Die ursprüngliche Idee war es, die Schwierigkeit eines dem Modell von Rasch entsprechenden Items auf die Schwierigkeit jener kognitiven Fertigkeiten zurückzuführen, die aufgrund theoretischer Überlegungen im Vorfeld der Lösung des Items zugrunde liegen.



Zur Kontrolle der Gültigkeit des LLTM werden die laut LLTM geschätzten Parameter mit den aus dem dichotom logistischen Modell von Rasch mit Hilfe einer der bereits bekannten Modellkontrollen verglichen.
Der bekannteste Test, der auf dem LLTM basiert ist der Wiener Matrizen Test (WMT) von Formann und Piswanger (1979).
Abgesehen von der ursprünglichen Idee, kann das LLTM auch z.B. für den Vergleich von Gruppen, Positionseffekten, oder zur Modellierung des Einflusses von Lernprozessen (Veränderungsmessung) verwendet werden.
Die ursprüngliche Idee war es, die Schwierigkeit eines dem Modell von Rasch entsprechenden Items auf die Schwierigkeit jener kognitiven Fertigkeiten zurückzuführen, die aufgrund theoretischer Überlegungen im Vorfeld der Lösung des Items zugrunde liegen.
Zur Kontrolle der Gültigkeit des LLTM werden die laut LLTM geschätzten Parameter mit den aus dem dichotom logistischen Modell von Rasch mit Hilfe einer der bereits bekannten Modellkontrollen verglichen.
Der bekannteste Test, der auf dem LLTM basiert ist der Wiener Matrizen Test (WMT) von Formann und Piswanger (1979).
Abgesehen von der ursprünglichen Idee, kann das LLTM auch z.B. für den Vergleich von Gruppen, Positionseffekten, oder zur Modellierung des Einflusses von Lernprozessen (Veränderungsmessung) verwendet werden.
Tags: IRT, LLTM, Rasch-Modell
Quelle: F318
Quelle: F318
Berechne die Itemschwierigkeiten für jedes Item:

Die ursprüngliche Idee war es, die Schwierigkeit eines dem Modell von Rasch entsprechenden Items auf die Schwierigkeit jener kognitiven Fertigkeiten zurückzuführen, die aufgrund theoretischer Überlegungen im Vorfeld der Lösung des Items zugrunde liegen.



Tags: IRT, Itemschwierigkeit, LLTM
Quelle: F318
Quelle: F318
Was ist das Partial Credit Modell?
Das Partial Credit Model ist das Rasch Modell für ordinale Daten. Die dahinter liegende Idee ist eine Verallgemeinerung des dichotom logistischen Modells von Rasch. Für letzteres wurde gezeigt, dass es neben der IC Kurve für das Lösen des Items auch eine IC Kurve für das nicht Lösen eines Items gibt.

Hat man nun nicht nur zwei, sondern z.B. vier Kategorien, könnten die resultierenden IC Kurven folgendermaßen aussehen.

Dadurch wird für jeden Fähigkeitsparameter die Wahrscheinlichkeit der Antwort in Kategorie x modelliert.
Jene Stellen, ab denen eine andere Kategorie als wahrscheinlichste gilt, werden Schwellen genannt.
Prinzipiell können die Schwellen in jedem Item anders sein.
Da daraus eine sehr große Zahl an Parameter resultiert, können zusätzliche Annahmen getroffen werden, die zu unterschiedlichen Modellen führen. Diese sind
Mittels das Partial Credit Modells kann geprüft werden, ob die Stufen eines Items tatsächlich rangskaliert sind. Die Ordnung der Antwortkategorien zeigt sich daran, dass die Schnittpunkte zweier benachbarter Kategorien „geordnet“ sind. Das bedeutet, dass z.B. der Übergang von Kategorie 0 auf 1 bei einer niedrigeren Personenfähigkeit erfolgt, als der Übergang von Kategorie 1 auf 2 usw.

Hat man nun nicht nur zwei, sondern z.B. vier Kategorien, könnten die resultierenden IC Kurven folgendermaßen aussehen.
Dadurch wird für jeden Fähigkeitsparameter die Wahrscheinlichkeit der Antwort in Kategorie x modelliert.
Jene Stellen, ab denen eine andere Kategorie als wahrscheinlichste gilt, werden Schwellen genannt.
Prinzipiell können die Schwellen in jedem Item anders sein.
Da daraus eine sehr große Zahl an Parameter resultiert, können zusätzliche Annahmen getroffen werden, die zu unterschiedlichen Modellen führen. Diese sind
- das Ratingskalen Modell,
- das Äquidstanzmodell und
- das Dispersionsmodell.
Mittels das Partial Credit Modells kann geprüft werden, ob die Stufen eines Items tatsächlich rangskaliert sind. Die Ordnung der Antwortkategorien zeigt sich daran, dass die Schnittpunkte zweier benachbarter Kategorien „geordnet“ sind. Das bedeutet, dass z.B. der Übergang von Kategorie 0 auf 1 bei einer niedrigeren Personenfähigkeit erfolgt, als der Übergang von Kategorie 1 auf 2 usw.
Tags: IRT, Partial Credit Modell, Rasch-Modell
Quelle: F322
Quelle: F322
Welche Arten von Modellen gibt es beim Partial Credit Modell?
Prinzipiell können die Schwellen in jedem Item anders sein.
Da daraus eine sehr große Zahl an Parameter resultiert, können zusätzliche Annahmen getroffen werden, die zu unterschiedlichen Modellen führen. Diese sind




Mittels das Partial Credit Modells kann geprüft werden, ob die Stufen eines Items tatsächlich rangskaliert sind. Die Ordnung der Antwortkategorien zeigt sich daran, dass die Schnittpunkte zweier benachbarter Kategorien „geordnet“ sind. Das bedeutet, dass z.B. der Übergang von Kategorie 0 auf 1 bei einer niedrigeren Personenfähigkeit erfolgt, als der Übergang von Kategorie 1 auf 2 usw.

Da daraus eine sehr große Zahl an Parameter resultiert, können zusätzliche Annahmen getroffen werden, die zu unterschiedlichen Modellen führen. Diese sind
- das Ratingskalen Modell,
- das Äquidstanzmodell und
- das Dispersionsmodell.
Mittels das Partial Credit Modells kann geprüft werden, ob die Stufen eines Items tatsächlich rangskaliert sind. Die Ordnung der Antwortkategorien zeigt sich daran, dass die Schnittpunkte zweier benachbarter Kategorien „geordnet“ sind. Das bedeutet, dass z.B. der Übergang von Kategorie 0 auf 1 bei einer niedrigeren Personenfähigkeit erfolgt, als der Übergang von Kategorie 1 auf 2 usw.
Tags: IRT, Partial Credit Modell
Quelle: F325
Quelle: F325
Kartensatzinfo:
Autor: coster
Oberthema: Psychologie
Thema: Testtheorie
Schule / Uni: Universität Wien
Ort: Wien
Veröffentlicht: 12.06.2013
Schlagwörter Karten:
Alle Karten (187)
adaptive Testen (1)
adaptiver Test (1)
adaptives Testen (1)
apparativer Test (1)
Axiome (6)
Berechnung (20)
Birnbaum Modelle (1)
Definition (18)
Eigenwert (5)
Erwartungswert (1)
Existenzaxiom (1)
Faktorenanalyse (21)
Faktorenrotation (3)
Faktorenzahl (1)
Faktorwert (1)
Faktorwerte (1)
Fragebogen (2)
Guttman-Skala (4)
Häufigkeit (1)
Hypothese (2)
IRT (32)
Itemanalyse (9)
Itemkonstruktion (3)
Itemtrennschärfe (3)
Itemvarianz (2)
Kennwert (2)
Kennwerte (1)
Kommunalität (2)
Korrelation (3)
Kosten-Nutzen (1)
Kovarianz (1)
Kritik (1)
Ladung (2)
Leistungstest (1)
Likelihood (4)
LLTM (2)
LQT (1)
Marker-Item (1)
Martin Löf Test (1)
Merkmal (3)
Messung (1)
Mittelwert (1)
Modellkontrolle (1)
Modellkontrollen (7)
Normalverteilung (1)
Normierung (4)
Normwerte (5)
Objektivität (5)
Parallelität (1)
Population (2)
projektiver Test (1)
Prozentränge (2)
Rasch-Modell (26)
Regression (1)
Reliabilität (26)
Routineverfahren (2)
Skalenniveau (2)
Skalierung (1)
Spearman-Brown (3)
Stichprobe (1)
Test (8)
Testarten (1)
Testkonstruktion (2)
Tests (1)
Testtheorie (1)
Validität (28)
Varianz (4)
Wissenschaft (2)
z-Test (2)
z-Wert (2)
