

Was sind die Beispiele für varianzanalytische Methoden?
– Einfaktorielle Versuchspläne
– Einzelvergleiche (Kontraste) und Post-Hoc-Tests
– Zweifaktorielle Versuchspläne – Haupteffekte & Wechselwirkungen
– Simultaner Vergleich von 2 Gruppen zu 2 Zeitpunkten (klassisches Design der Interventionsforschung) – abhängige Messungen
– (Ausblick auf) Kovarianzanalyse
– Einzelvergleiche (Kontraste) und Post-Hoc-Tests
– Zweifaktorielle Versuchspläne – Haupteffekte & Wechselwirkungen
– Simultaner Vergleich von 2 Gruppen zu 2 Zeitpunkten (klassisches Design der Interventionsforschung) – abhängige Messungen
– (Ausblick auf) Kovarianzanalyse
Tags: Varianzanalyse
Quelle: VO01
Quelle: VO01
Was versteht man unter der einfaktoriellen Varianzanalyse? Nenne ein Beispiel und die Vorteile der Durchführung einer einfaktoriellen Varianzanalyse.
- Einfaktorielle Varianzanalyse (ANOVA) erlaubt simultanen Vergleich von k ≥ 2 Mittelwerten
- „Erweiterung“ des t-Test für k > 2 Gruppen

Warum keine drei t-Tests (Depressive vs. Remittierte; Depressive vs. Gesunde; Remittierte vs. Gesunde) ?
Problem der Alphafehler-Kumulierung Jeder statistische Test hat (selbstgewählte) Irrtumswahrscheinlichkeit Alphafehler/Fehler 1. Art (meistens: α = 0.05)
Der gemeinsame Fehler (familywise error) ist fast dreimal höher als der nominell gewählte. Die Zuwachsrate steigt mit Anzahl der Gruppen und Vergleiche stark an.
Für den simultanen Vergleich mehrerer Gruppenmittelwerte ist ANOVA somit das geeignete Analyseinstrument
– Kontrolliert den familywise error
– Ist aber nicht so konservativ wie alternative Prozeduren
Tags: ANOVA, Varianzanalyse
Quelle: VO01
Quelle: VO01
Warum ist beim simultanen Vergleich mehrerer Gruppenmittelwerte die ANOVA sinnvoll und nicht der Einsatz mehrerer t-Tests?

Warum keine drei t-Tests (Depressive vs. Remittierte; Depressive vs. Gesunde; Remittierte vs. Gesunde) ?

Problem der Alphafehler-Kumulierung
Jeder statistische Test hat (selbstgewählte) Irrtumswahrscheinlichkeit: Alphafehler/Fehler 1. Art (meistens: α = 0.05)
Wenn die
 in Wirklichkeit gilt, wird sie (dennoch) in (nur) 5 von 100 Fällen verworfen (bei α = 0.05)
in Wirklichkeit gilt, wird sie (dennoch) in (nur) 5 von 100 Fällen verworfen (bei α = 0.05)Der Alphafehler von drei t-Tests zusammen ist somit sicherlich größer als jener bloß eines (t-)Tests - Nur:Wie groß ?
Annahme: Ergebnisse der t-Tests voneinander statistisch unabhängig
Wahrscheinlichkeit für einen Alphafehler bei einem Test ist gleich α

Statistische Unabhängigkeit - Multiplikationstheorem
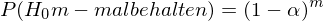
Gegenwahrscheinlichkeit: in m Tests mindestens einmal die
(fälschlicherweise) verwerfen
α = 0.05, k = 3 Gruppen, m = 3 t-Tests

Der gemeinsame Fehler (familywise error) ist fast dreimal höher als der nominell gewählte.
Zuwachsrate steigt mit Anzahl der Gruppen und Vergleiche stark an:

Zudem: nicht alle Tests voneinander unabhängig reales Alpha höher!
Zur Kontrolle des familywise error können Prozeduren wie Bonferroni-Korrektur o. ä. verwendet werden - JEDOCH sehr konservatives Verfahren.
Für den simultanen Vergleich mehrerer Gruppenmittelwerte ist ANOVA somit das geeignete Analyseinstrument
– Kontrolliert den familywise error
– Ist aber nicht so konservativ wie alternative Prozeduren
Tags: ANOVA, t-Test, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was versteht man unter einem familywise error?
Darunter versteht man den Fehler der akkumuliert wird wenn ein Test mehrfach auf eine Hypothese angewendet wird.
Warum keine drei t-Tests (Depressive vs. Remittierte; Depressive vs. Gesunde; Remittierte vs. Gesunde) ?
Problem der Alphafehler-Kumulierung
Jeder statistische Test hat (selbstgewählte) Irrtumswahrscheinlichkeit - Alphafehler/Fehler 1. Art (meistens: α = 0.05)
Beispiel:
α = 0.05, k = 3 Gruppen, m = 3 t-Tests
Der gemeinsame Fehler (familywise error) ist fast dreimal höher als der nominell gewählte.
Zur Kontrolle des familywise error können Prozeduren wie Bonferroni-Korrektur o. ä. verwendet werden.
Warum keine drei t-Tests (Depressive vs. Remittierte; Depressive vs. Gesunde; Remittierte vs. Gesunde) ?
Problem der Alphafehler-Kumulierung
Jeder statistische Test hat (selbstgewählte) Irrtumswahrscheinlichkeit - Alphafehler/Fehler 1. Art (meistens: α = 0.05)
Beispiel:
α = 0.05, k = 3 Gruppen, m = 3 t-Tests
Der gemeinsame Fehler (familywise error) ist fast dreimal höher als der nominell gewählte.
Zur Kontrolle des familywise error können Prozeduren wie Bonferroni-Korrektur o. ä. verwendet werden.
Tags: ANOVA, Fehler, t-Test, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was ist die Bonferroni-Korrektur?
Zur Kontrolle des familywise error können Prozeduren wie Bonferroni-Korrektur o. ä. verwendet werden.

Nachteil: Sehr konservatives Vorgehen! (Verwerfen der H0 wird u. U. unverhältnismäßig schwierig; k = 3, α = 0.05: α* = 0.017)
Für den simultanen Vergleich mehrerer Gruppenmittelwerte ist ANOVA somit das geeignete Analyseinstrument
– Kontrolliert den familywise error
– Ist aber nicht so konservativ wie alternative Prozeduren
Nachteil: Sehr konservatives Vorgehen! (Verwerfen der H0 wird u. U. unverhältnismäßig schwierig; k = 3, α = 0.05: α* = 0.017)
Für den simultanen Vergleich mehrerer Gruppenmittelwerte ist ANOVA somit das geeignete Analyseinstrument
– Kontrolliert den familywise error
– Ist aber nicht so konservativ wie alternative Prozeduren
Tags: ANOVA, t-Test, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was ist das Prinzip der Varianzanalyse?
Omnibustest
ANOVA prüft nicht sequentiell die Hypothesen
H0(1): μ1 = μ2 ; H0(2): μ1 = μ3 ; H0(3): μ2 = μ3 sondern
H0: μ1= μ2 = μ3 bzw. allgemein H0: μ1 = μ2 = … = μk
Die H1 wird angenommen, wenn sich zumindest zwei der untersuchten Mittelwerte signifikant voneinander unterscheiden

Test beruht auf einem Vergleich der Varianz der Daten, die durch
systematische Unterschiede bedingt wird (Gruppen), gegenüber der Varianz, die durch den Zufall zustande kommt → „Varianzanalyse“
Ist die Varianz der Gruppenmittelwerte um einen gemeinsamen Mittelwert größer als die Varianz innerhalb der Gruppen?
Beispiel: Depressive (rot) / Remittierte (blau) / Gesunde (grün)
Gruppenmittelwerte um einen gemeinsamen Mittelwert:

Varianz innerhalb der Gruppe:

ANOVA prüft nicht sequentiell die Hypothesen
H0(1): μ1 = μ2 ; H0(2): μ1 = μ3 ; H0(3): μ2 = μ3 sondern
H0: μ1= μ2 = μ3 bzw. allgemein H0: μ1 = μ2 = … = μk
Die H1 wird angenommen, wenn sich zumindest zwei der untersuchten Mittelwerte signifikant voneinander unterscheiden
Test beruht auf einem Vergleich der Varianz der Daten, die durch
systematische Unterschiede bedingt wird (Gruppen), gegenüber der Varianz, die durch den Zufall zustande kommt → „Varianzanalyse“
Ist die Varianz der Gruppenmittelwerte um einen gemeinsamen Mittelwert größer als die Varianz innerhalb der Gruppen?
Beispiel: Depressive (rot) / Remittierte (blau) / Gesunde (grün)
Gruppenmittelwerte um einen gemeinsamen Mittelwert:
Varianz innerhalb der Gruppe:
Tags: ANOVA, Varianzanalyse
Quelle: VO01
Quelle: VO01

Tags: ANOVA, Signifikanz, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was zeigt dieser SPSS Auszug:



Interpretation: die Gruppen unterscheiden sich signifikant voneinander
- H0 wird verworfen
- Welche Gruppen zeigen signifikante Unterschiede?
Einzelvergleiche (Kontraste) und Post-Hoc-Tests
Tags: ANOVA, SPSS, Varianzanalyse
Quelle: VO01
Quelle: VO01
Welche Methoden können bei der Varianzanalyse verwendet werden um festzustellen zwischen welchen Gruppen es signifikante Unterschiede gibt?
- Einzelvergleiche (Kontraste)
- Post-Hoc-Tests
Einzelvergleiche häufig a priori formuliert, d.h. bereits vor Durchführung der Analyse besteht eine Hypothese, welche Mittelwerte sich voneinander unterscheiden sollten (hypothesengeleitetes Vorgehen)
Einzelvergleiche können aber auch a posteriori berechnet werden, ebenso wie Post-Hoc-Tests zur Datenexploration benutzt werden können (exploratives Vorgehen)
Tags: Einzelvergleiche, Post-Hoc-Test, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was sind Einzelvergleiche bei der Varianzanalyse und wie werden diese durchgeführt?
Einzelvergleiche = Kontraste
Erlauben spezifische Gruppenvergleiche und auch gerichtete Hypothesen z.B.: Gesunde und Remittierte haben niedrigere Werte im BDI-II als akut Depressive
Rechnerische Durchführung durch Festlegung von Linearkombinationen bzw. gewichteter Summen der Gruppenmittelwerte

Zwei Kontraste sind orthogonal, wenn die Summe der Produkte ihrer Koeffizienten Null ist:

Beispiel SPSS:

(Die Kontrast-Koeffizienten sind die Gewichtung. Wenn zwei Gruppen den gleichen Kontrast-Koeffizienten haben, dann werden diese zusammengelegt und gegen die andere verglichen.
Kontrast 2: Depressive sind nicht relevant – deshalb haben sie das Gewicht 0
Ergebnis der Kontrasttests ist
Kontraste können für sequentielle Vergleiche von Gruppenmittelwerten verwendet werden.
Einseitige oder zweiseitige Testung in Kontrasten richtet sich nach dem Vorhandensein gerichteter Hypothesen
Erlauben spezifische Gruppenvergleiche und auch gerichtete Hypothesen z.B.: Gesunde und Remittierte haben niedrigere Werte im BDI-II als akut Depressive
Rechnerische Durchführung durch Festlegung von Linearkombinationen bzw. gewichteter Summen der Gruppenmittelwerte
- Orthogonale (= unabhängige) und nicht-orthogonale Kontraste möglich
- Allgemein:

Zwei Kontraste sind orthogonal, wenn die Summe der Produkte ihrer Koeffizienten Null ist:
Beispiel SPSS:
(Die Kontrast-Koeffizienten sind die Gewichtung. Wenn zwei Gruppen den gleichen Kontrast-Koeffizienten haben, dann werden diese zusammengelegt und gegen die andere verglichen.
Kontrast 2: Depressive sind nicht relevant – deshalb haben sie das Gewicht 0
Ergebnis der Kontrasttests ist
- Gesunde und Remittierte unterscheiden sich signifikant von Depressiven; einseitige Testung → p-Wert kann noch halbiert werden (t-Verteilung!)
- Gesunde unterscheiden sich auch signifikant von Remittierten; keine a priori Hypothese → Beibehalten des 2-seitigen p-Wertes aus SPSS
Kontraste können für sequentielle Vergleiche von Gruppenmittelwerten verwendet werden.
- Ausschluss jeweils einer Gruppe in nachfolgenden Kontrasttests (Kontrastkoeffizient = 0)
- stellt sicher, dass alle Kontraste orthogonal (= unabhängig) sind
Einseitige oder zweiseitige Testung in Kontrasten richtet sich nach dem Vorhandensein gerichteter Hypothesen
Tags: Einzelvergleich, Varianzanalyse
Quelle: VO01
Quelle: VO01
Was kennzeichnet varianzanalytische Methoden im Allgemeinen? Welche Erweiterungen des ALM gibt es?
Varianzanalytische Designs zählen zu den wichtigsten Auswertungsmethoden der gesamten Statistik
- Erlauben die Untersuchung vielfältiger Fragestellungen
- Hohe Flexibilität in der Anwendung
- Allgemeines lineares Modell (ALM) hat jedoch Einschränkungen (Verteilungsannahmen, Homoskedastizität, Linearität, …)
- Erweiterungen des allgemeinen linearen Modells (ALM): - Generalized Linear Model (GLM[GenLin]: Verteilung der abhängigen Variable kann anders als normal sein; Linearität der UV nicht zwingend notwendig)- Generalized Linear Mixed Model (GLMM/GEE: Erweiterung fester Effekte um zufällige; Modellierung unterschiedlichster abhängiger Datenstrukturen (z.B. Verletzung der Sphärizität möglich))
Tags: ALM, Varianzanalyse
Quelle: VO04
Quelle: VO04
Kartensatzinfo:
Autor: coster
Oberthema: Psychologie
Thema: Statistik
Schule / Uni: Universität Wien
Ort: Wien
Veröffentlicht: 21.06.2013
Schlagwörter Karten:
Alle Karten (175)
4-Felder-Tafel (17)
abhängige Daten (6)
ALM (1)
ANCOVA (3)
ANOVA (15)
Bindung (1)
Cohens d (10)
Cohens Kappa (6)
Effektgröße (31)
Einzelvergleich (2)
Einzelvergleiche (1)
Eta (7)
Fehler (1)
Friedman-Test (3)
H-Test (5)
Haupteffekt (2)
Haupteffekte (1)
Interaktion (5)
Konkordanz (4)
Kontrast (11)
Kontrollvariable (1)
MANOVA (2)
McNemar-Test (4)
Mediantest (5)
Medientest (1)
mixed ANOVA (10)
NNT (3)
Normalverteilung (3)
NPV (4)
Nulldifferenzen (1)
odds ratio (7)
partielle Eta (5)
phi-Koeffizient (1)
Phi-Koeffizienz (1)
Planung (1)
Post-Hoc-Test (4)
Post-hoc-Tests (3)
Power (1)
PPV (4)
Prävalenz (6)
r (4)
Reliabilität (1)
risk ratio (7)
Sensitivität (6)
Signifikanz (6)
Spezifität (6)
Sphärizität (2)
SPSS (14)
SPss (1)
Stichprobe (3)
Störvariable (1)
t-Test (7)
Testmacht (2)
Trends (1)
U-Test (6)
Varianz (2)
Varianzanalyse (11)
Varianzschätzer (1)
Voraussetzungen (2)
Vorzeichentest (2)
Wechselwirkung (3)
Wilcoxon-Test (4)
x2-Test (5)
